资料
App爬虫是怎么着情况
前面我们介绍的都是爬取 Web 网页的内容。随着移动互联网的发展,越来越多的企业并没有提供 Web 网页端的服务,而是直接开发了 App,更多更全的信息都是通过 App 来展示的。那么针对 App 我们可以爬取吗?当然可以。
我们知道 Web 站点有多种渲染和反爬方式,渲染分为服务端渲染和客户端渲染;反爬也是多种多样,如请求头验证、WebDriver 限制、验证码、字体反爬、封禁 IP、账号验证等等,综合来看 Web 端的反爬虫方案也是多种多样。
但 App 的情况略有不同,一般来说,App 的数据通信大都需要依赖独立的服务器,比如请求某个 HTTP 接口来获取数据或做登录校验等。这种通信其实就类似 Web 中的 Ajax,客户端向服务器发起 HTTP 请求,获取到数据之后再做一些处理,数据的格式大多也是 JSON、XML 等,基本不会有 HTML 代码这样的数据。
所以说,对于 App 来说,其核心就在于找到这些数据请求到底是怎样的,比如某次 HTTP POST 请求的 URL、Headers、Data 等等,知道了这些,我们就能用程序模拟这个请求过程,从而就能完成爬虫了。
那么怎么知道 App 到底在运行过程中发起了什么请求呢?最有效且常见的方式就是抓包了,抓包工具也非常多,比如 Fiddler、Charles、mitmproxy、anyproxy 等等,我们用这些工具抓到 HTTP 请求包,就能看到这个请求的 Method、Headers、Data 等内容了,知道了之后再用程序模拟出来就行了。
但是,这个过程中你可能遇到非常多的问题,毕竟 App 的数据也是非常宝贵的,所以一些 App 也添加了各种反爬措施,比如:
- 这个 App 的请求根本抓不到包,原因可能是 App 本身设置了不走系统代理。
- 对一些 HTTPS 的请求,抓包失败,原因可能是系统或 App 本身设置了 SSL Pining,对 HTTPS 证书进行了校验,代理软件证书校验不通过,拒绝连接。
- 某些包即使抓到了,也发现了其中带了加密参数,比如 sign、token 等等,难以直接用程序模拟。
- 为了破解一些加密参数可能需要对 App 进行逆向,逆向后发现是混淆后的代码,难以分析逻辑。
- 一些 App 为了防止逆向,本身进行了加固,需要对 App 进行脱壳处理才能进行后续操作。
- 一些 App 将核心代码进行编译,形成 so 库,因此可能需要对 so 库进行逆向才能了解其逻辑。
- 一些 App 和其服务器对以上所有的流程进行了风控处理,如果发现有疑似逆向或破解或访问频率等问题,返回一些假数据或拒绝服务,导致爬虫难以进行。
随着移动互联网的发展,App 上承载的数据也越来越多,越来越重要,很多厂商为了保护 App 的数据也采取了非常多的手段。因此 App 的爬取和逆向分析也变得越来越难,本课时我们就来梳理一些 App 爬取方案。
以下内容针对 Android 平台。
抓包
对于多数情况来说,一台 Android 7.0 版本以下的手机,抓一些普通的 App 的请求包还是很容易做到的。
抓包的工具有很多,常见的如 Charles、Fiddler、mitmproxy 等。
抓包的时候在 PC 端运行抓包软件,抓包软件会开启一个 HTTP 代理服务器,然后手机和 PC 连在同一个局域网内,设置好抓包软件代理的 IP 和端口,另外 PC 和手机都安装抓包软件的证书并设置信任。这样在手机上再打开 App 就能看到 App 在运行过程中发起的请求了。
抓包完成之后在抓包软件中定位到具体数据包,查看其详情,了解其请求 Method、URL、Headers、Data,如果这些没有什么加密参数的话,我们用 Python 重写一遍就好了。
当然如果遇到抓不到包或者有加密参数的情形,无法直接重写,那就要用到后面介绍的方法了。
抓不到包
一些 App 在内部实现的时候对代理加了一些校验,如绕过系统代理直接连接或者检测到了使用了代理,直接拒绝连接。
这种情形往往是手机的 HTTP 客户端对系统的网络环境做了一些判断,并修改了一些 HTTP 请求方式,使得数据不走代理,这样抓包软件就没法直接抓包了。
另外对于一些非 HTTP 请求的协议,利用常规的抓包软件也可能抓不到包。这里提供一些解决方案。
强制全局代理
虽然有些数据包不走代理,但其下层还是基于 TCP 协议的,所以可以将 TCP 数据包重定向到代理服务器。比如软件 ProxyDroid 就可以实现这样的操作,这样我们就能抓到数据包了。
ProxyDroid:https://github.com/madeye/proxydroid
手机代理
如果不通过 PC 上的抓包软件设置代理,还可以直接在手机上设置抓包软件,这种方式是通过 VPN 的方式将网络包转发给手机本地的代理服务器,代理服务器将数据发送给服务端,获取数据之后再返回即可。
使用了 VPN 的方式,我们就可以截获到对应的数据包了,一些工具包括 HttpCanary、Packet Capture、NetKeeper 等。
- HttpCanary:https://play.google.com/store/apps/details?id=com.guoshi.httpcanary
- Packet Capture:https://play.google.com/store/apps/details?id=app.greyshirts.sslcapture
- NetKeeper:https://play.google.com/store/apps/details?id=com.minhui.networkcapture.pro
以上应用链接来源于 Google Play,也可以在国内应用商店搜索或直接下载 apk 安装。
特殊协议抓包
可以考虑使用 Wireshark、Tcpdump 在更底层的协议上抓包,比如抓取 TCP、UDP 数据包等等。
使用的时候建议直接 PC 上开热点,然后直接抓取 PC 无线网卡的数据包,这样 App 不管有没有做系统代理校验或者使用了非 HTTP 协议,都能抓到数据包了。
SSL Pining
SSL Pining,就是证书绑定,这个只针对 HTTPS 请求。
SSL Pining 发生在下面的一些情况:
- 对于 Android 7.0 以上的手机,系统做了改动,HTTPS 请求只信任系统级别证书,这会导致系统安全性增加,但是由于抓包软件的证书并不是系统级别证书,就不受信任了,那就没法抓包了。
- 一些 App 里面专门写了逻辑对 SSL Pining 做了处理,对 HTTPS 证书做了校验,如果发现是不在信任范围之内的,那就拒绝连接。
对于这些操作,我们通常有两种思路来解决:
- 让系统信任我们的 HTTPS 证书;
- 绕开 HTTPS 证书的校验过程。
对于这两种思路,有以下一些绕过 SSL Pining 的解决方案。
修改 App 的配置
如果是 App 的开发者或者把 apk 逆向出来了,那么可以直接通过修改 AndroidManifest.xml 文件,在 apk 里面添加证书的信任规则即可,详情可以参考 https://crifan.github.io/app_capture_package_tool_charles/website/how_capture_app/complex_https/https_ssl_pinning/,这种思路属于第一种信任证书的解决方案。
将证书设置为系统证书
当然也可以将证书直接设置为系统证书,只需要将抓包软件的证书设置为系统区域即可。但这个前提是手机必须要 ROOT,而且需要计算证书 Hash Code 并对证书进行重命名,具体可以参考 https://crifan.github.io/app_capture_package_tool_charles/website/how_capture_app/complex_https/https_ssl_pinning,这种思路也是第一种信任证书的解决方案。
Xposed + JustTrustMe
Xposed 是一款 Android 端的 Hook 工具,利用它我们可以 Hook App 里面的关键方法的执行逻辑,绕过 HTTPS 的证书校验过程。JustTrustMe 是基于 Xposed 一个插件,它可以将 HTTPS 证书校验的部分进行 Hook,改写其中的证书校验逻辑,这种思路是属于第二种绕过 HTTPS 证书校验的解决方案。
当然基于 Xposed 的类似插件也有很多,如 SSLKiller、sslunpining 等等,可以自行搜索。
不过 Xposed 的安装必须要 ROOT,如果不想 ROOT 的话,可以使用后文介绍的 VirtualXposed。
Frida
Frida 也是一种类似 Xposed 的 Hook 软件,使用它我们也可以实现一些 HTTPS 证书校验逻辑的改写,这种思路也是属于第二种绕过 HTTPS 证书校验的方案。
具体可以参考 https://codeshare.frida.re/@pcipolloni/universal-android-ssl-pinning-bypass-with-frida/。
VirtualXposed
Xposed 的使用需要 ROOT,如果不想 ROOT 的话,可以直接使用一款基于 VirtualApp 开发的 VirtualXposed 工具,它提供了一个虚拟环境,内置了 Xposed。我们只需要将想要的软件安装到 VirtualXposed 里面就能使用 Xposed 的功能了,然后配合 JustTrustMe 插件也能解决 SSL Pining 的问题,这种思路是属于第二种绕过 HTTPS 证书校验的解决方案。
特殊改写
对于第二种绕过 HTTPS 证书校验的解决方案,其实本质上是对一些关键的校验方法进行了 Hook 和改写,去除了一些校验逻辑。但是对于一些代码混淆后的 App 来说,其校验 HTTPS 证书的方法名直接变了,那么 JustTrustMe 这样的插件就无法 Hook 这些方法,因此也就无效了。
所以这种 App 可以直接去逆向,找到其中的一些校验逻辑,然后修改写 JustTrustMe 的源码就可以成功 Hook 住了,也就可以重新生效了。
逆向秘钥
还有一种硬解的方法,可以直接逆向 App,反编译得到证书秘钥,使用秘钥来解决证书限制。
逆向
以上解决了一些抓包的问题,但是还有一个问题,就是抓的数据包里面带有加密参数怎么办?比如一个 HTTP 请求,其参数还带有 token、sign 等参数,即使我们抓到包了,那也没法直接模拟啊?
所以我们可能需要对 App 进行一些逆向分析,找出这些加密过程究竟是怎样的。这时候我们就需要用到一些逆向工具了。
JEB
JEB 是一款适用于 Android 应用程序和本机机器代码的反汇编器和反编译器软件。利用它我们可以直接将安卓的 apk 反编译得到 Smali 代码、jar 文件,获取到 Java 代码。有了 Java 代码,我们就能分析其中的加密逻辑了。
JEB:https://www.pnfsoftware.com/
JADX
与 JEB 类似,JADX 也是一款安卓反编译软件,可以将 apk 反编译得到 jar 文件,得到 Java 代码,从而进一步分析逻辑。
JADX:https://github.com/skylot/jadx
dex2jar、jd-gui
这两者通常会配合使用来进行反编译,同样也可以实现 apk 文件的反编译,但其用起来个人感觉不如 JEB、JADX 方便。
脱壳
一些 apk 可能进行了加固处理,所以在反编译之前需要进行脱壳处理。一般来说可以先借助于一些查壳工具查壳,如果有壳的话可以借助于 Dumpdex、FRIDA-DEXDump 等工具进行脱壳。
- FRIDA-DEXDump:https://github.com/hluwa/FRIDA-DEXDump
- Dumpdex:https://github.com/WrBug/dumpDex
反汇编
一些 apk 里面的加密可能直接写入 so 格式的动态链接库里面,要想破解其中的逻辑,就需要用到反汇编的一些知识了,这里可以借助于 IDA 这个软件来进行分析。
IDA:https://www.hex-rays.com/
以上的一些逆向操作需要较深的功底和安全知识,在很多情况下,如果逆向成功了,一些加密算法还是能够被找出来的,找出来了加密逻辑之后,我们用程序模拟就方便了。
模拟
逆向对于多数有保护 App 是有一定作用的,但有的时候 App 还增加了风控检测,一旦 App 检测到运行环境或访问频率等信息出现异常,那么 App 或服务器就可能产生防护,直接停止执行或者服务器返回假数据等都是有可能的。
对于这种情形,有时候我们就需要回归本源,真实模拟一些 App 的手工操作了。
adb
最常规的 adb 命令可以实现一些手机自动化操作,但功能有限。
触动精灵、按键精灵
有很多商家提供了手机 App 的一些自动化脚本和驱动,如触动精灵、按键精灵等,利用它们的一些服务我们可以自动化地完成一些 App 的操作。
触动精灵:https://www.touchsprite.com/
Appium
类似 Selenium,Appium 是手机上的一款移动端的自动化测试工具,也能做到可见即可爬的操作。
Appium:http://appium.io/
AirTest
同样是一款移动端的自动化测试工具,是网易公司开发的,相比 Appium 来说使用更方便。
AirTest:http://airtest.netease.com/
Appium/AirTest + mitmdump
mitmdump 其实是一款抓包软件,与 mitmproxy 是一套工具。这款软件配合自动化的一些操作就可以用 Python 实现实时抓包处理了。
mitmdump:https://mitmproxy.readthedocs.io/
到此,App 的一些爬虫思路和常用的工具就介绍完了,在后面的课时我们会使用其中一些工具来进行实战演练。
参考来源
- https://zhuanlan.zhihu.com/webspider
- https://www.zhihu.com/question/60618756/answer/492263766
- https://www.jianshu.com/p/a818a0d0aa9f
- https://mp.weixin.qq.com/s/O6iWb2VL4SH9UNLwk2FCMw
- https://zhuanlan.zhihu.com/p/60392573
- https://crifan.github.io/app_capture_package_tool_charles/website/
- https://github.com/WooyunDota/DroidDrops/blob/master/2018/SSL.Pinning.Practice.md
本课时我们主要学习如何使用 Charles。
Charles 是一个网络抓包工具,我们可以用它来做 App 的抓包分析,得到 App 运行过程中发生的所有网络请求和响应内容,这就和 Web 端浏览器的开发者工具 Network 部分看到的结果一致。
Charles、Fiddler 等都是非常强大的 HTTP 抓包软件,功能基本类似,不过 Charles 的跨平台支持更好。所以我们选用 Charles 作为主要的移动端抓包工具,用于分析移动 App 的数据包,辅助完成 App 数据抓取工作。
本节目标
本节我们以电影示例 App 为例,通过 Charles 抓取 App 运行过程中的网络数据包,然后查看具体的 Request 和 Response 内容,以此来了解 Charles 的用法。
同时抓取到数据包之后,我们采用 Python 将请求进行改写,从而实现 App 数据的爬取。
准备工作
请确保已经正确安装 Charles 并开启了代理服务,另外准备一部 Android 手机,系统版本最好是在 7.0 以下。
如果系统版本在 7.0 及以上,可能出现 SSL Pining 的问题,可以参考第一课时的思路来解决。
然后手机连接 Wi-Fi,和 PC 处于同一个局域网下,另外将 Charles 代理和 Charles CA 证书设置好,同时需要开启 SSL 监听。
此过程的配置流程可以参见:https://cuiqingcai.com/5255.html。
最后手机上安装本节提供的 apk(apk 随课件一同领取),进行接下来的 Charles 抓包操作。
原理
首先将 Charles 运行在自己的 PC 上,Charles 运行的时候会在 PC 的 8888 端口开启一个代理服务,这个服务实际上是一个 HTTP/HTTPS 的代理。
确保手机和 PC 在同一个局域网内,我们可以使用手机模拟器通过虚拟网络连接,也可以使用手机真机和 PC 通过无线网络连接。
设置手机代理为 Charles 的代理地址,这样手机访问互联网的数据包就会流经 Charles,Charles 再转发这些数据包到真实的服务器,服务器返回的数据包再由 Charles 转发回手机,Charles 就起到中间人的作用,所有流量包都可以捕捉到,因此所有 HTTP 请求和响应都可以捕获到。同时 Charles 还有权力对请求和响应进行修改。
抓包
好,我们先打开 Charles,初始状态下 Charles 的运行界面如图所示。
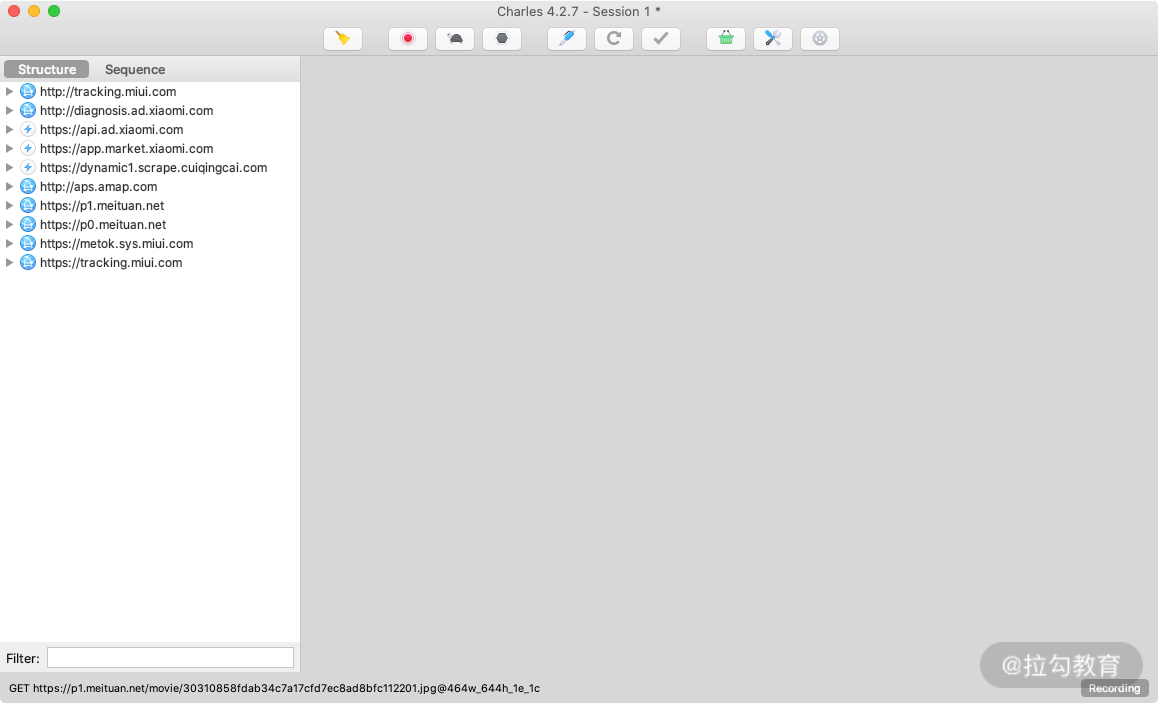
Charles 会一直监听 PC 和手机发生的网络数据包,捕获到的数据包就会显示在左侧,随着时间的推移,捕获的数据包越来越多,左侧列表的内容也会越来越多。
可以看到,图中左侧显示了 Charles 抓取到的请求站点,我们点击任意一个条目便可以查看对应请求的详细信息,其中包括 Request、Response 等内容。
接下来清空 Charles 的抓取结果,点击左侧的扫帚按钮即可清空当前捕获到的所有请求。然后点击第二个监听按钮,确保监听按钮是打开的,这表示 Charles 正在监听 App 的网络数据流,如图所示。
这时打开 App,注意一定要提前设置好 Charles 的代理并配置好 CA 证书,否则没有效果。
打开 App 之后我们就可以看到类似如下的页面。
这时候我们就可以发现 Charles 里面已经抓取到了对应的数据包,出现了类似如图所示的结果。
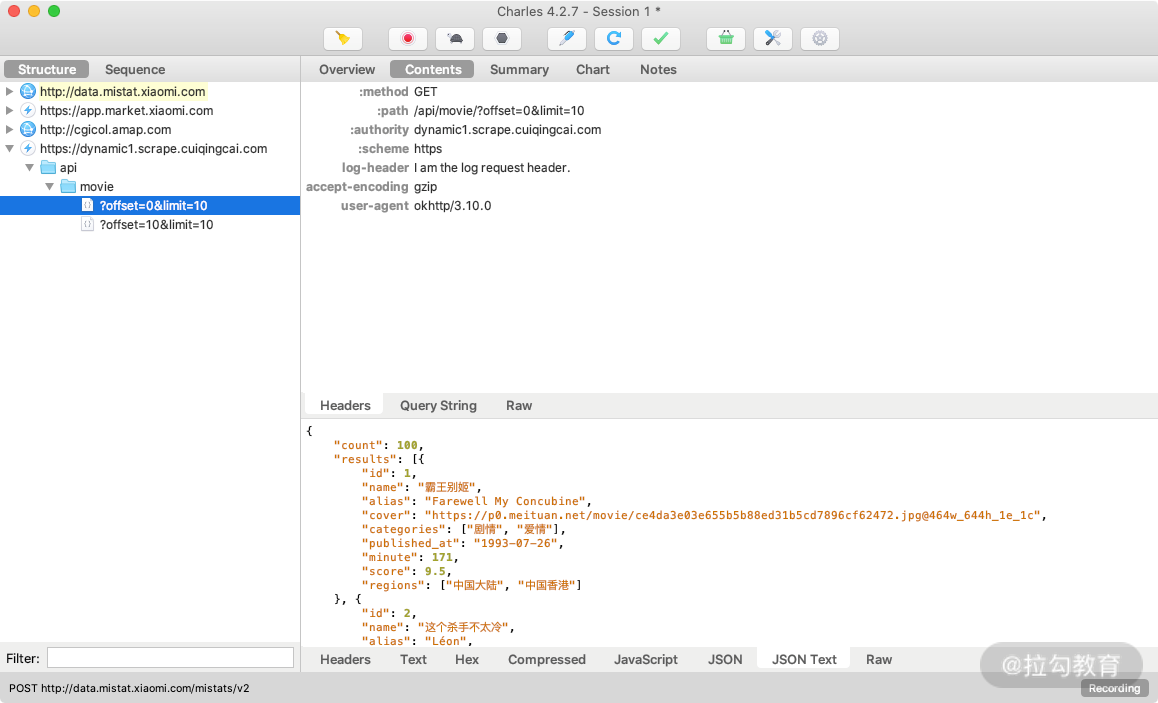
我们在 App 里不断上拉,可以看到 Charles 捕获到这个过程中 App 内发生的所有网络请求,如图所示。
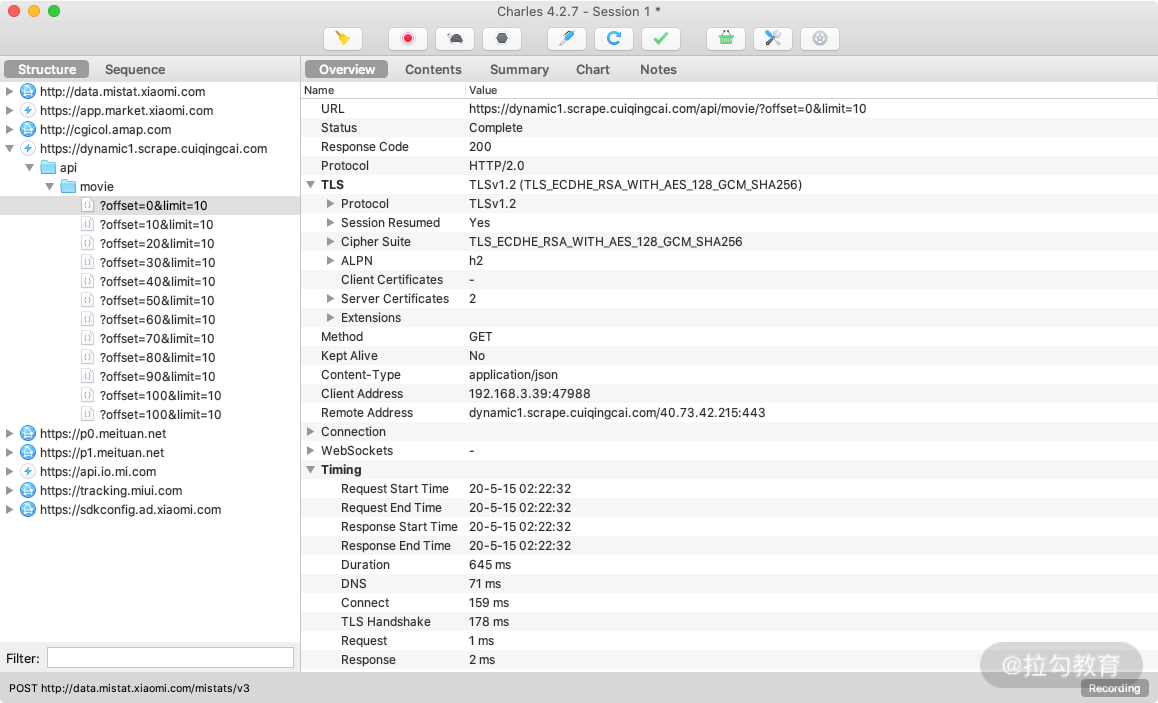
左侧列表中会出现一个 dynamic1.scrape.center 的链接,而且在 App 上拉过程它在不停闪动,这就是当前 App 发出的获取数据的请求被 Charles 捕获到了。
为了验证其正确性,我们点击查看其中一个条目的详情信息。切换到 Contents 选项卡,这时我们发现一些 JSON 数据,核对一下结果,结果有 results 字段,每一个条目的 name 字段就是电影的信息,这与 App 里面呈现的内容是完全一致的,如图所示。
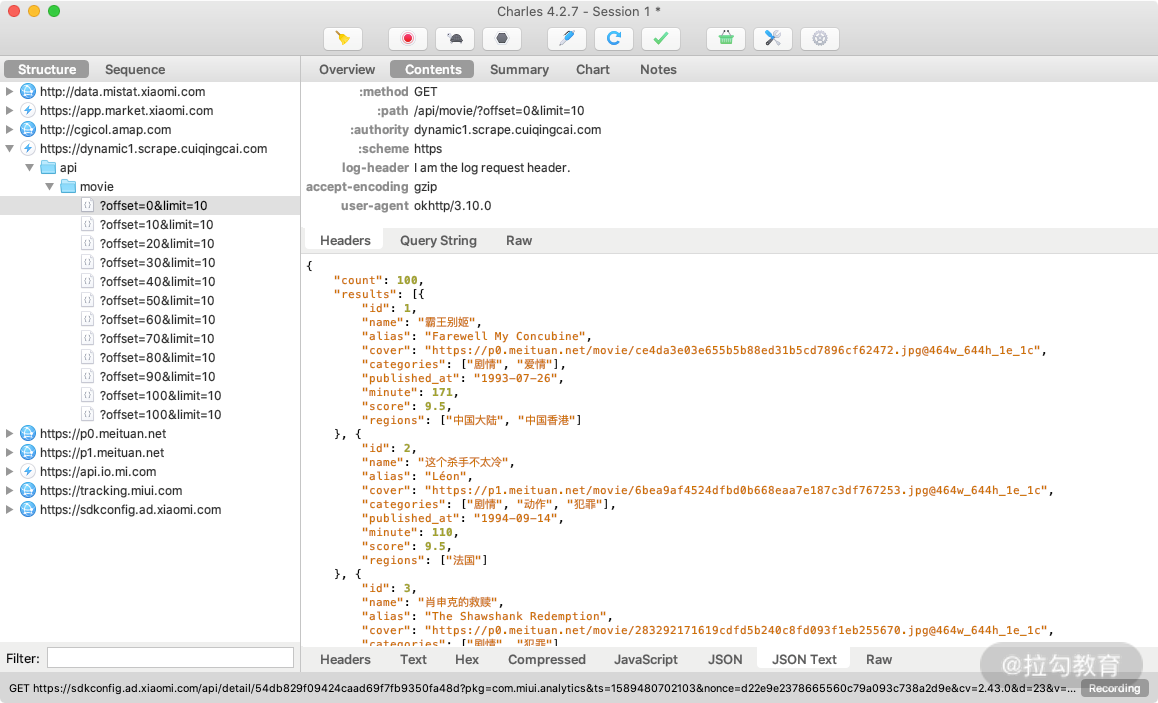
这时可以确定,此请求对应的接口就是获取电影数据的接口。这样我们就成功捕获到了在上拉刷新的过程中发生的请求和响应内容。
分析
现在分析一下这个请求和响应的详细信息。首先可以回到 Overview 选项卡,上方显示了请求的接口 URL,接着是响应状态 Status Code、请求方式 Method 等,如图所示。
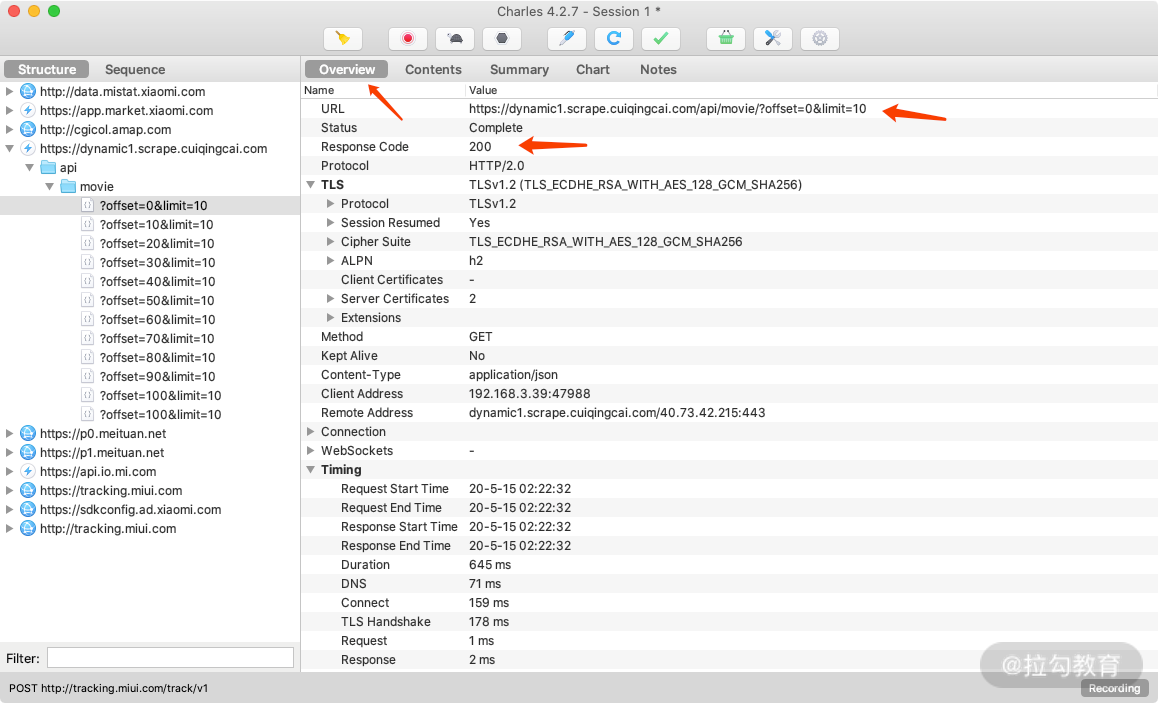
这个结果和原本在 Web 端用浏览器开发者工具内捕获到的结果形式是类似的。
接下来点击 Contents 选项卡,查看该请求和响应的详情信息。
上半部分显示的是 Request 的信息,下半部分显示的是 Response 的信息。比如针对 Reqeust,我们切换到 Headers 选项卡即可看到该 Request 的 Headers 信息,针对 Response,我们切换到 JSON Text 选项卡即可看到该 Response 的 Body 信息,并且该内容已经被格式化,如图所示。
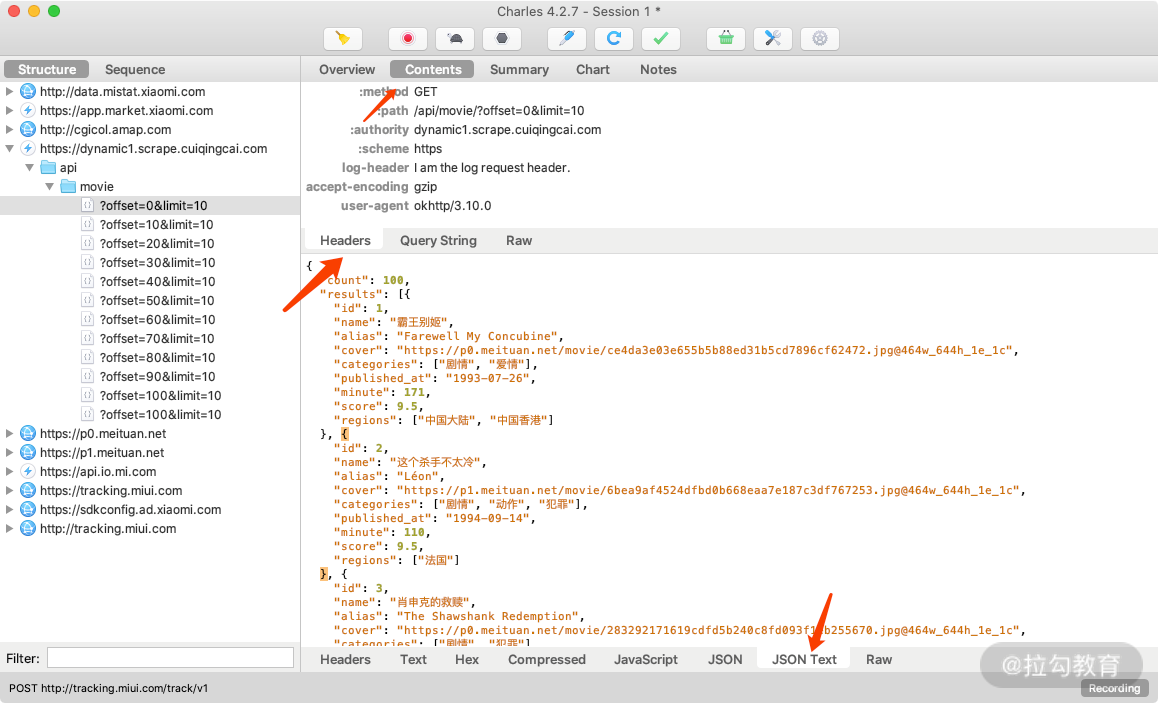
由于这个请求是 GET 请求,所以我们还需要关心的就是 GET 的参数信息,切换到 Query String 选项卡即可查看,如图所示。
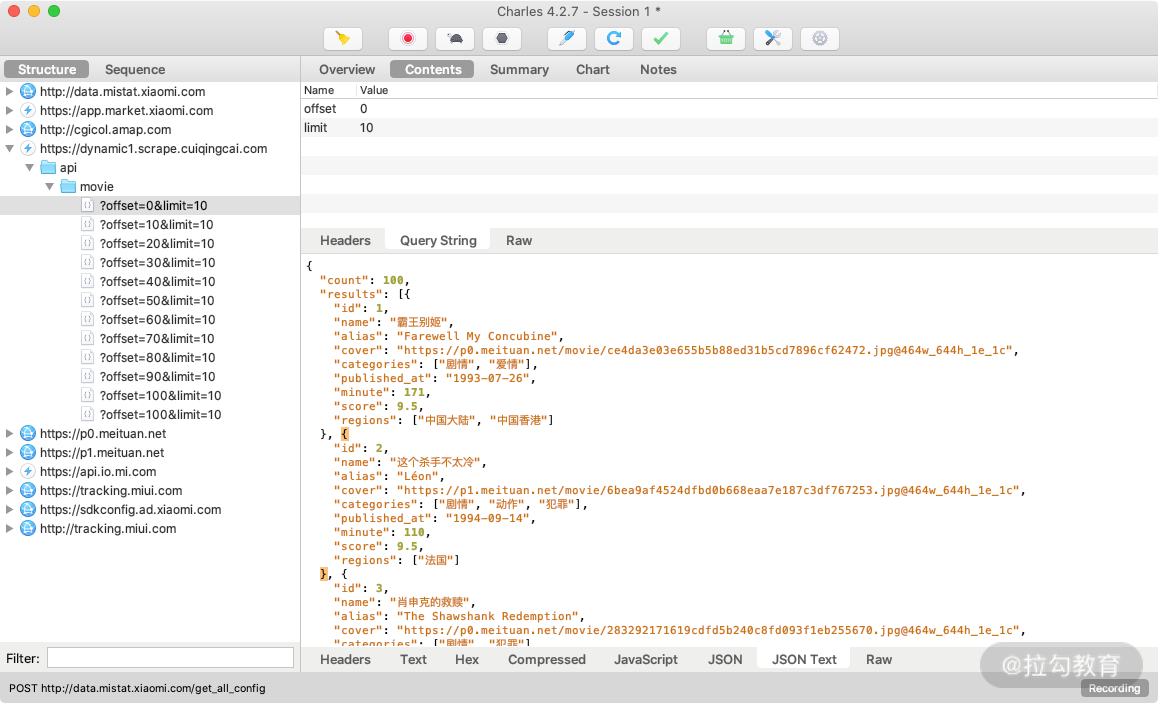
这样我们就成功抓取到了 App 中的电影数据接口的请求和响应,并且可以查看 Response 返回的 JSON 数据。
至于其他 App,我们同样可以使用这样的方式来分析。如果我们可以直接分析得到请求的 URL 和参数的规律,直接用程序模拟即可批量抓取。
重发
Charles 还有一个强大功能,它可以将捕获到的请求加以修改并发送修改后的请求。点击上方的修改按钮,左侧列表就多了一个以编辑图标为开头的链接,这就代表此链接对应的请求正在被我们修改,如图所示。
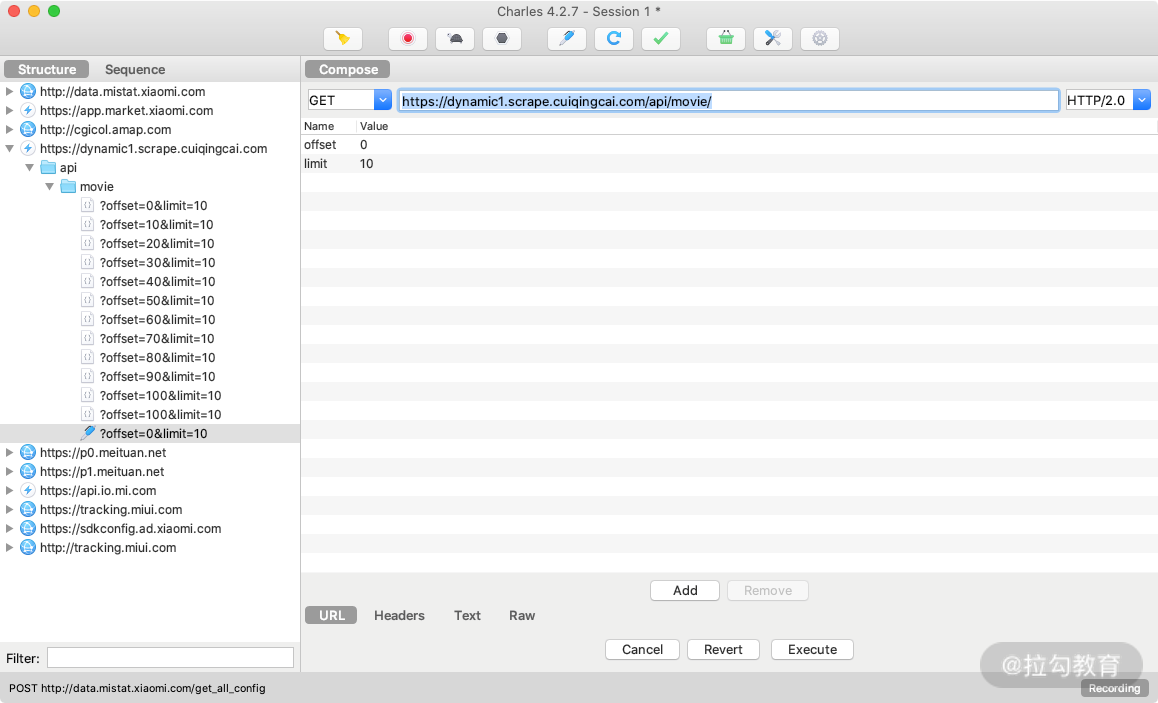
我们可以将参数中的某个字段修改下,比如这里将 offset 字段由 0 修改为 10。这时我们已经对原来请求携带的 Query 参数做了修改,然后点击下方的 Execute 按钮即可执行修改后的请求,如图所示。
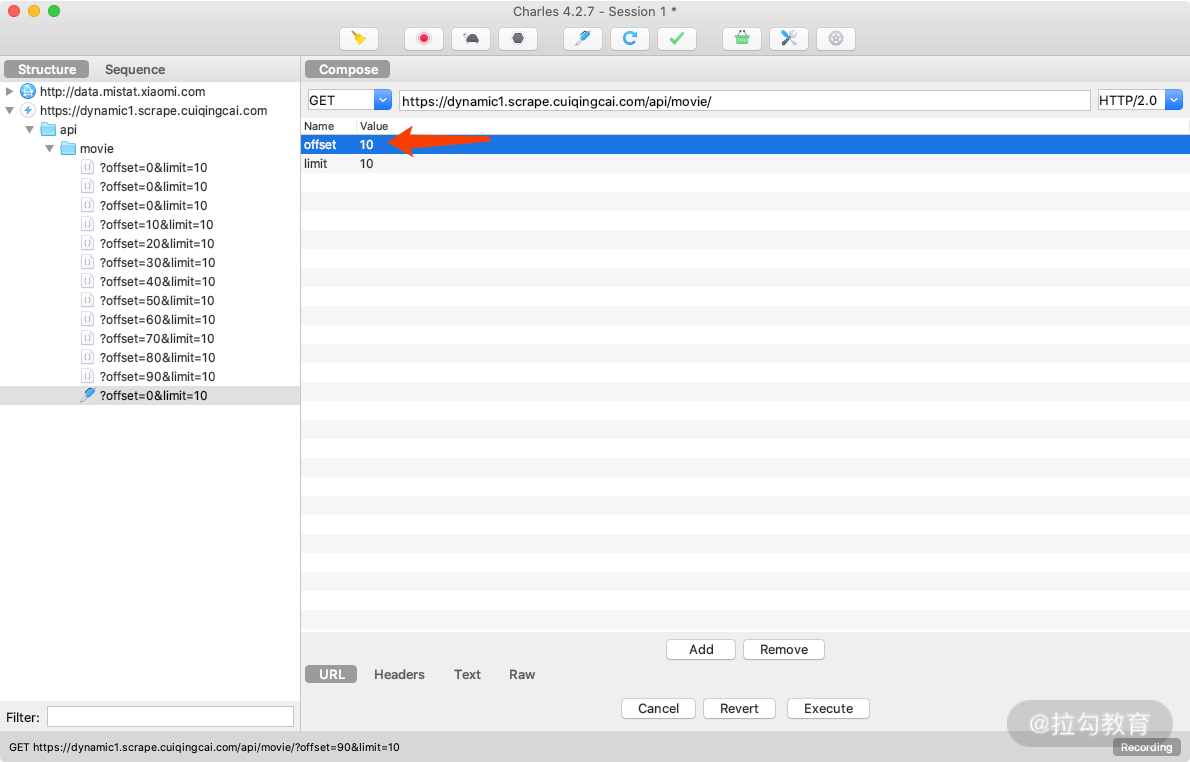
可以发现左侧列表再次出现了接口的请求结果,内容变成了第 11~20 条内容,如图所示。
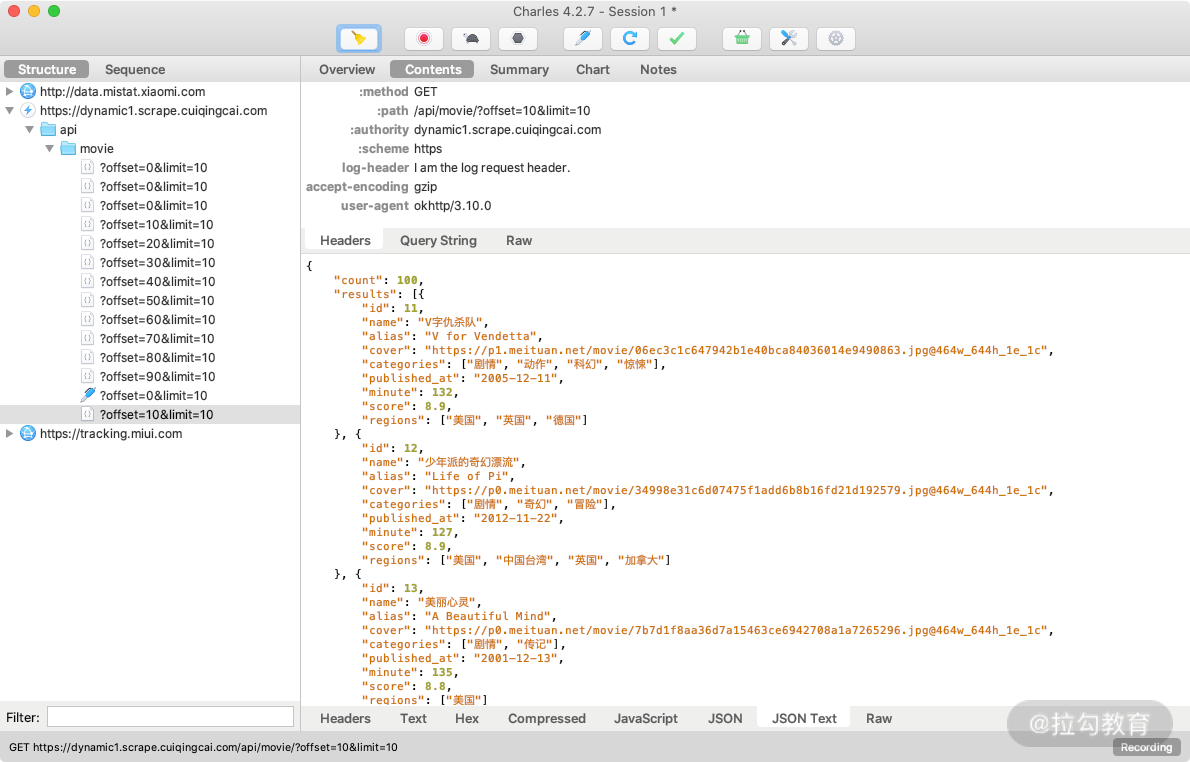
有了这个功能,我们就可以方便地使用 Charles 来做调试,可以通过修改参数、接口等来测试不同请求的响应状态,就可以知道哪些参数是必要的哪些是不必要的,以及参数分别有什么规律,最后得到一个最简单的接口和参数形式以供程序模拟调用使用。
模拟
现在我们已经成功完成了抓包操作了,所有的请求一目了然,请求的 URL 就是 https://dynamic1.scrape.center/api/movie/,后面跟了两个 GET 请求参数。经过观察,可以很轻松地发现 offset 就是偏移量,limit 就是一次请求要返回的结果数量。比如 offset 为 20,limit 为 10,就代表获取第 21~30 条数据。另外我们通过观察发现一共就是 100 条数据,offset 从 0 到 90 遍历即可。
接下来我们用 Python 简单实现一下模拟请求即可,这里写法一些从简了,代码如下:
import requests
BASE_URL = 'https://dynamic1.scrape.center/api/movie?offset={offset}&limit=10'
for i in range(0, 10):
offset = i * 10
url = BASE_URL.format(offset=offset)
data = requests.get(url).json()
print('data', data)
运行结果如下:
data {'count': 100, 'results': [{'id': 1, 'name': '霸王别姬', 'alias': 'Farewell My Concubine', 'cover': 'https://p0.meituan.net/movie/ce4da3e03e655b5b88ed31b5cd7896cf62472.jpg@464w_644h_1e_1c', 'categories': ['剧情', '爱情'], 'published_at': '1993-07-26', 'minute': 171, 'score': 9.5, 'regions': ['中国大陆', '中国香港']}, {'id': 2, 'name': '这个杀手不太冷', 'alias': 'Léon', 'cover': ... 'published_at': '1995-07-15', 'minute': 89, 'score': 9.0, 'regions': ['美国']}]}
data {'count': 100, 'results': [{'id': 11, 'name': 'V字仇杀队', 'alias': 'V for Vendetta', 'cover': 'https://p1.meituan.net/movie/06ec3c1c647942b1e40bca84036014e9490863.jpg@464w_644h_1e_1c', 'categories': ['剧情', '动作', '科幻', '惊悚'], 'published_at': '2005-12-11', 'minute': 132, 'score': 8.9, 'regions': ['美国', '英国', '德国']}, ... 'categories': ['纪录片'], 'published_at': '2001-12-12', 'minute': 98, 'score': 9.1, 'regions': ['法国', '德国', '意大利', '西班牙', '瑞士']}]}
data {'count': 100, 'results': [{'id': 21, 'name': '黄金三镖客', 'alias': 'Il buono, il brutto, il cattivo.', 'cover': ...
可以看到每个请求都被我们轻松模拟实现了,数据也被爬取下来了。
由于这个 App 的接口没有任何加密,所以仅仅靠抓包完之后观察规律我们就能轻松完成 App 接口的模拟爬取。
结语
以上内容便是通过 Charles 抓包分析 App 请求的过程。通过 Charles,我们成功抓取 App 中流经的网络数据包,捕获原始的数据,还可以修改原始请求和重新发起修改后的请求进行接口测试。
知道了请求和响应的具体信息,如果我们可以分析得到请求的 URL 和参数的规律,直接用程序模拟即可批量抓取,这当然最好不过了。
但是随着技术的发展,App 接口往往会带有密钥或者无法抓包,后面我们会继续讲解此类情形的处理操作。
实时处理利器mitmproxy的使用
在上一节课我们讲解了 Charles 的使用,它可以帮助我们抓取 HTTP 和 HTTPS 的数据包,抓到请求之后,我们如果能够分析出接口请求的一些规律,就能轻松通过 Python 脚本来进行改写。可是当请求里面包含一些无规律的参数的时候,可能就束手无策了。本节课我们介绍一个叫作 mitmproxy 的工具,它可以对抓包的结果通过脚本进行实时处理和保存,接下来我们来一起了解下吧。
介绍
mitmproxy 是一个支持 HTTP 和 HTTPS 的抓包程序,有类似 Fiddler、Charles 的功能,只不过它是一个控制台的形式操作。
mitmproxy 还有两个关联组件。一个是 mitmdump,它是 mitmproxy 的命令行接口,利用它我们可以对接 Python 脚本,用 Python 实现实时监听后的处理。另一个是 mitmweb,它是一个 Web 程序,通过它我们可以清楚观察 mitmproxy 捕获的请求。
下面我们来了解它们的用法。
准备工作
请确保已经正确安装好了 mitmproxy,并且手机和 PC 处于同一个局域网下,同时配置好了 mitmproxy 的 CA 证书,具体的配置可以参考 https://cuiqingcai.com/5391.html。
mitmproxy 的功能
mitmproxy 有如下几项功能。
- 拦截 HTTP 和 HTTPS 请求和响应;
- 保存 HTTP 会话并进行分析;
- 模拟客户端发起请求,模拟服务端返回响应;
- 利用反向代理将流量转发给指定的服务器;
- 支持 Mac 和 Linux 上的透明代理;
- 利用 Python 对 HTTP 请求和响应进行实时处理。
抓包原理
和 Charles 一样,mitmproxy 运行于自己的 PC 上,mitmproxy 会在 PC 的 8080 端口运行,然后开启一个代理服务,这个服务实际上是一个 HTTP/HTTPS 的代理。
手机和 PC 在同一个局域网内,设置代理为 mitmproxy 的代理地址,这样手机在访问互联网的时候流量数据包就会流经 mitmproxy,mitmproxy 再去转发这些数据包到真实的服务器,服务器返回数据包时再由 mitmproxy 转发回手机,这样 mitmproxy 就相当于起了中间人的作用,抓取到所有 Request 和 Response,另外这个过程还可以对接 mitmdump,抓取到的 Request 和 Response 的具体内容都可以直接用 Python 来处理,比如得到 Response 之后我们可以直接进行解析,然后存入数据库,这样就完成了数据的解析和存储过程。
设置代理
首先,我们需要运行 mitmproxy,mitmproxy 启动命令如下所示:
mitmproxy
运行之后会在 8080 端口上运行一个代理服务,如图所示:
右下角会出现当前正在监听的端口。
或者启动 mitmdump,它也会监听 8080 端口,命令如下所示:
mitmdump
运行结果如图所示。

将手机和 PC 连接在同一局域网下,设置代理为当前代理。首先看看 PC 的当前局域网 IP。
Windows 上的命令如下所示:
ipconfig
Linux 和 Mac 上的命令如下所示:
ifconfig
输出结果如图所示。

一般类似 10...* 或 172.16.. 或 192.168.1.* 这样的 IP 就是当前 PC 的局域网 IP,例如此图中 PC 的 IP 为 192.168.1.28,手机代理设置类似如图所示。
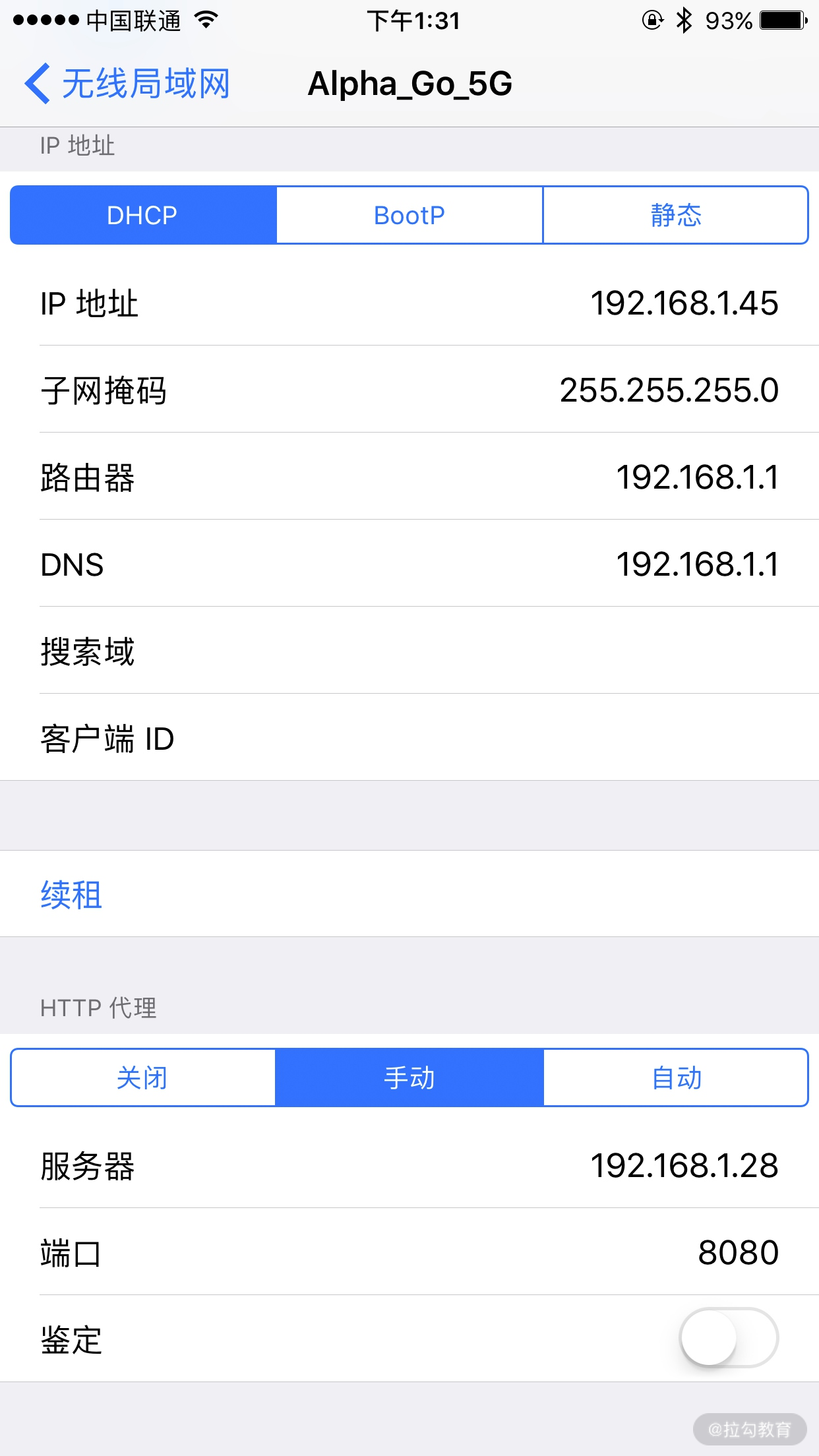
这样我们就配置好了 mitmproxy 的代理。
mitmproxy 的使用
确保 mitmproxy 正常运行,并且手机和 PC 处于同一个局域网内,设置了 mitmproxy 的代理。
运行 mitmproxy,命令如下所示:
mitmproxy
设置成功之后,我们只需要在手机浏览器上访问任意的网页或浏览任意的 App 即可。例如在手机上打开百度,mitmproxy 页面便会呈现出手机上的所有请求,如图所示。
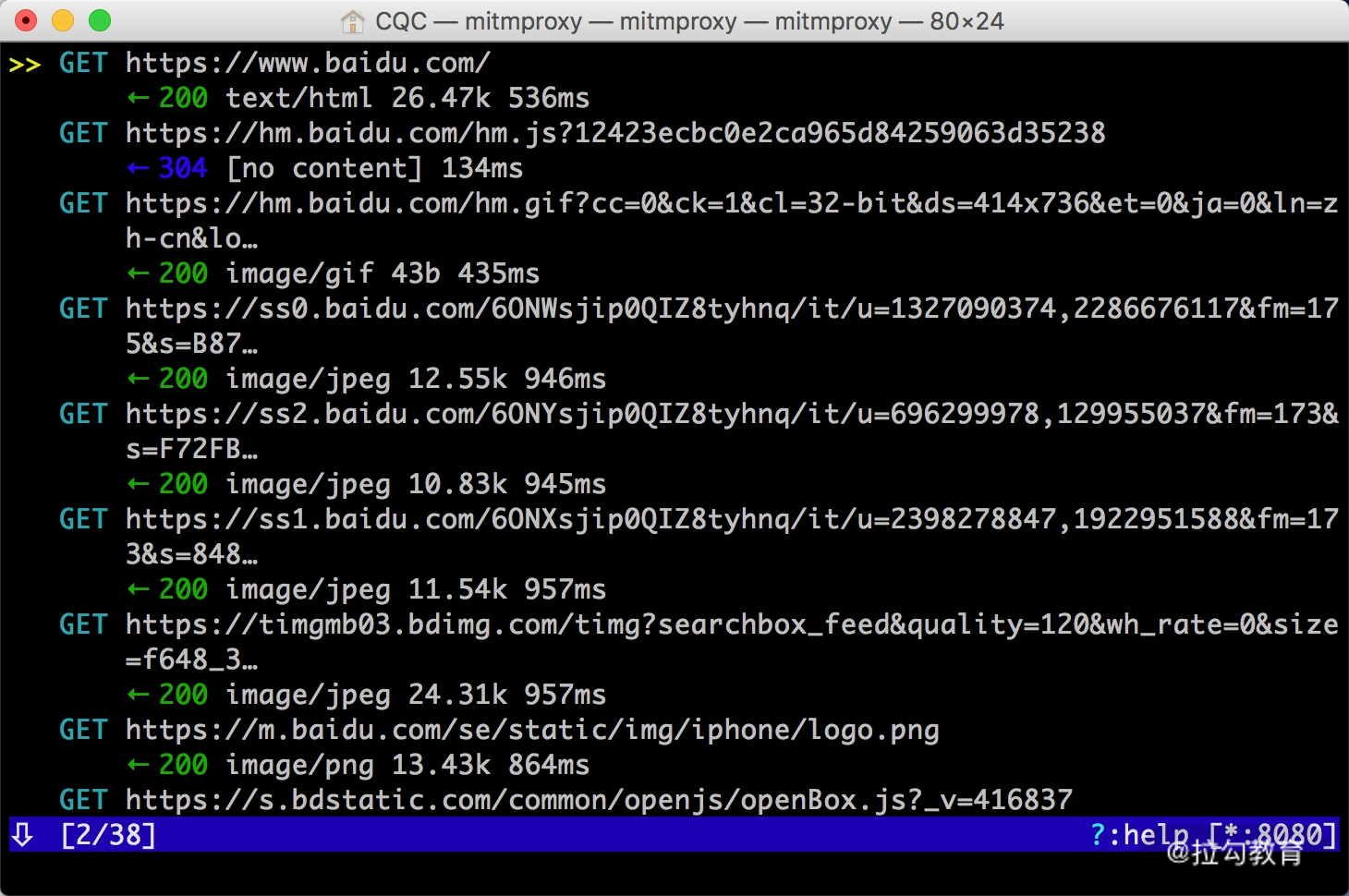
这就相当于之前我们在浏览器开发者工具监听到的浏览器请求,在这里我们借助于 mitmproxy 完成。Charles 完全也可以做到。
这里是刚才手机打开百度页面时的所有请求列表,左下角显示的 2/38 代表一共发生了 38 个请求,当前箭头所指的是第二个请求。
每个请求开头都有一个 GET 或 POST,这是各个请求的请求方式。紧接的是请求的 URL。第二行开头的数字就是请求对应的响应状态码,后面是响应内容的类型,如 text/html 代表网页文档、image/gif 代表图片。再往后是响应体的大小和响应的时间。
当前呈现了所有请求和响应的概览,我们可以通过这个页面观察到所有的请求。
如果想查看某个请求的详情,我们可以敲击回车,进入请求的详情页面,如图所示。
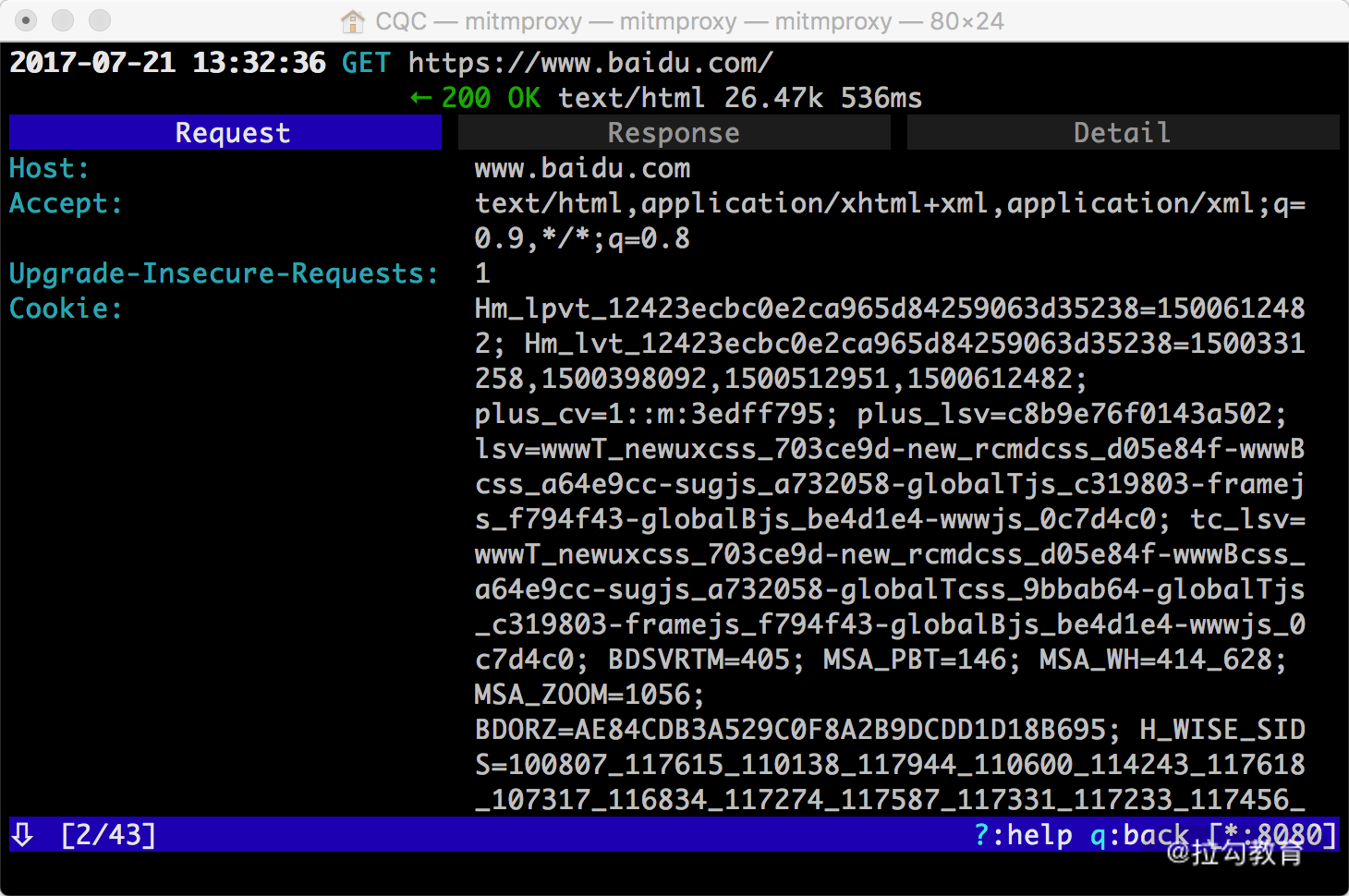
可以看到 Headers 的详细信息,如 Host、Cookies、User-Agent 等。
最上方是一个 Request、Response、Detail 的列表,当前处在 Request 这个选项上。这时我们再点击 Tab 键,即可查看这个请求对应的响应详情,如图所示。
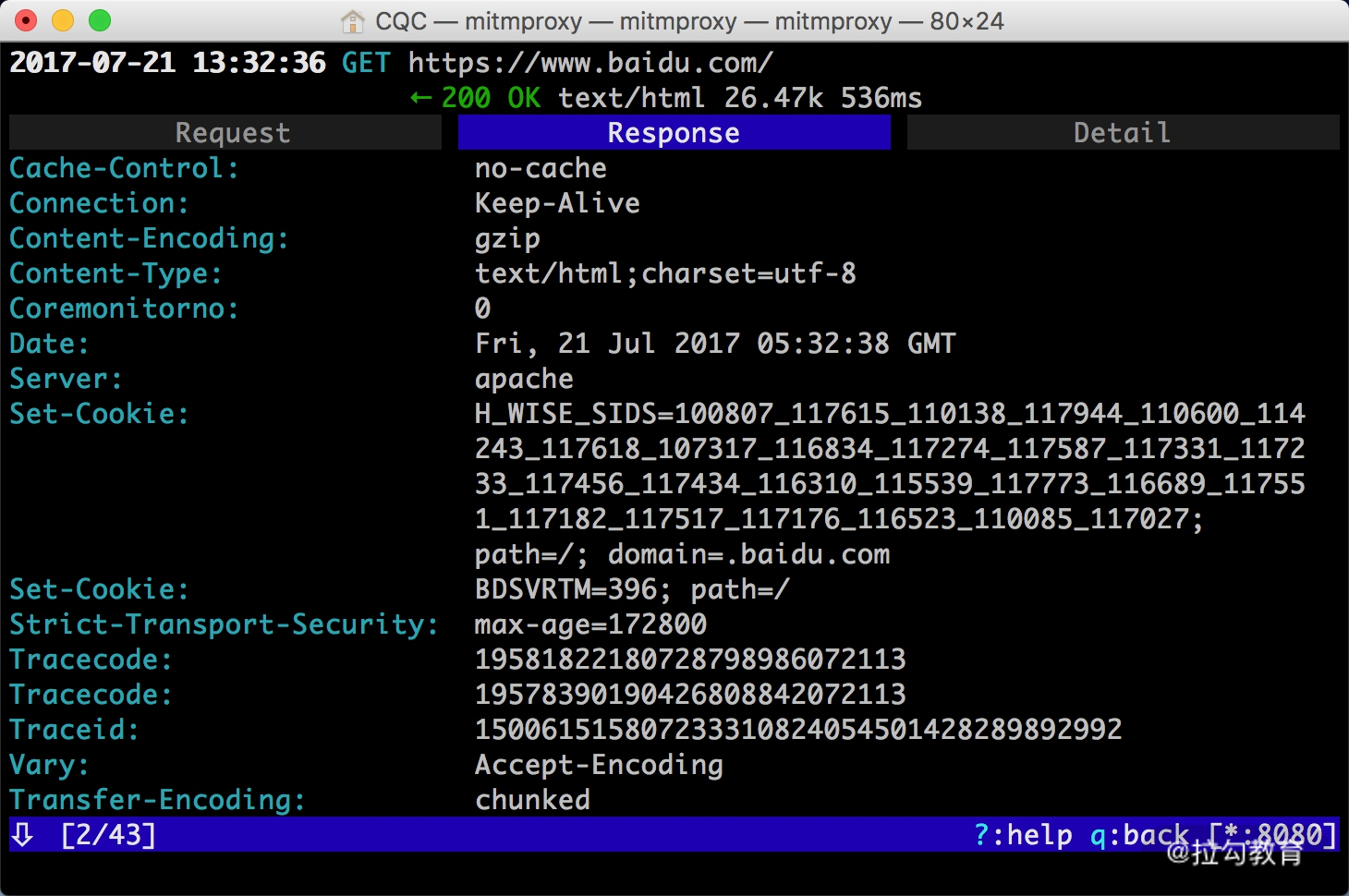
最上面是响应头的信息,下拉之后我们可以看到响应体的信息。针对当前请求,响应体就是网页的源代码。
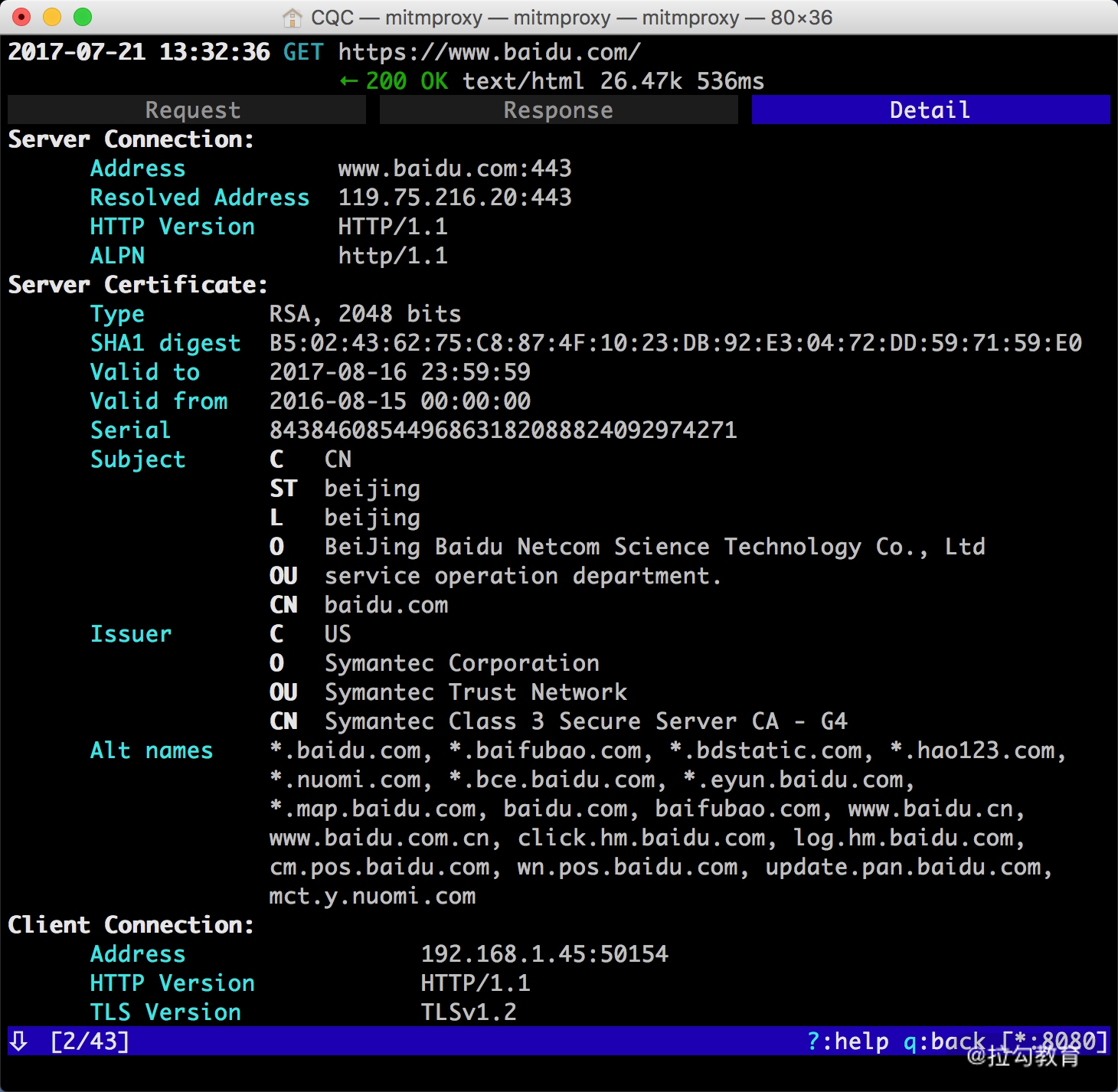
这时再敲击 Tab 键,切换到最后一个选项卡 Detail,即可看到当前请求的详细信息,如服务器的 IP 和端口、HTTP 协议版本、客户端的 IP 和端口等,如图所示。
mitmproxy 还提供了命令行式的编辑功能,我们可以在此页面中重新编辑请求。敲击 e 键即可进入编辑功能,这时它会询问你要编辑哪部分内容,如 Cookies、Query、URL 等,每个选项的第一个字母会高亮显示。敲击要编辑内容名称的首字母即可进入该内容的编辑页面,如敲击 m 即可编辑请求的方式,敲击 q 即可修改 GET 请求参数 Query。
这时我们敲击 q,进入到编辑 Query 的页面。由于没有任何参数,我们可以敲击 a 来增加一行,然后就可以输入参数对应的 Key 和 Value,如图所示。
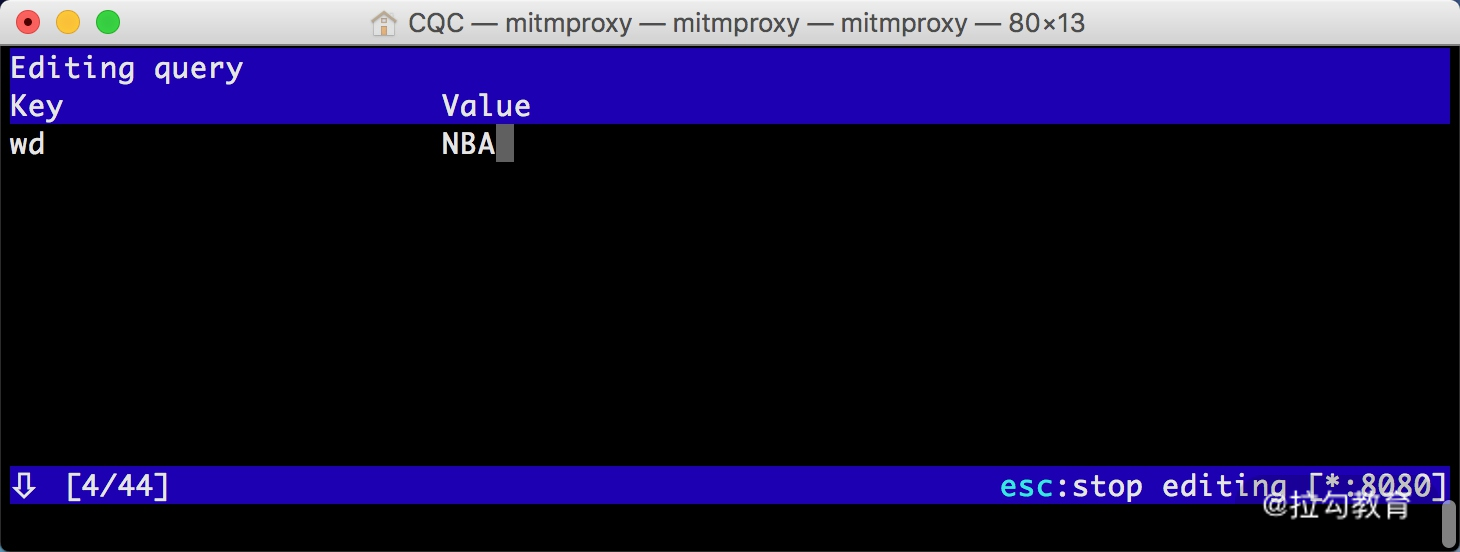
这里我们输入 Key 为 wd,Value 为 NBA。
然后再敲击 Esc 键和 q 键,返回之前的页面,再敲击 e 和 p 键修改 Path。和上面一样,敲击 a 增加 Path 的内容,这时我们将 Path 修改为 s,如图所示。
再敲击 esc 和 q 键返回,这时我们可以看到最上面的请求链接变成了 https://www.baidu.com/s?wd=NBA,访问这个页面,可以看到百度搜索 NBA 关键词的搜索结果,如图所示。
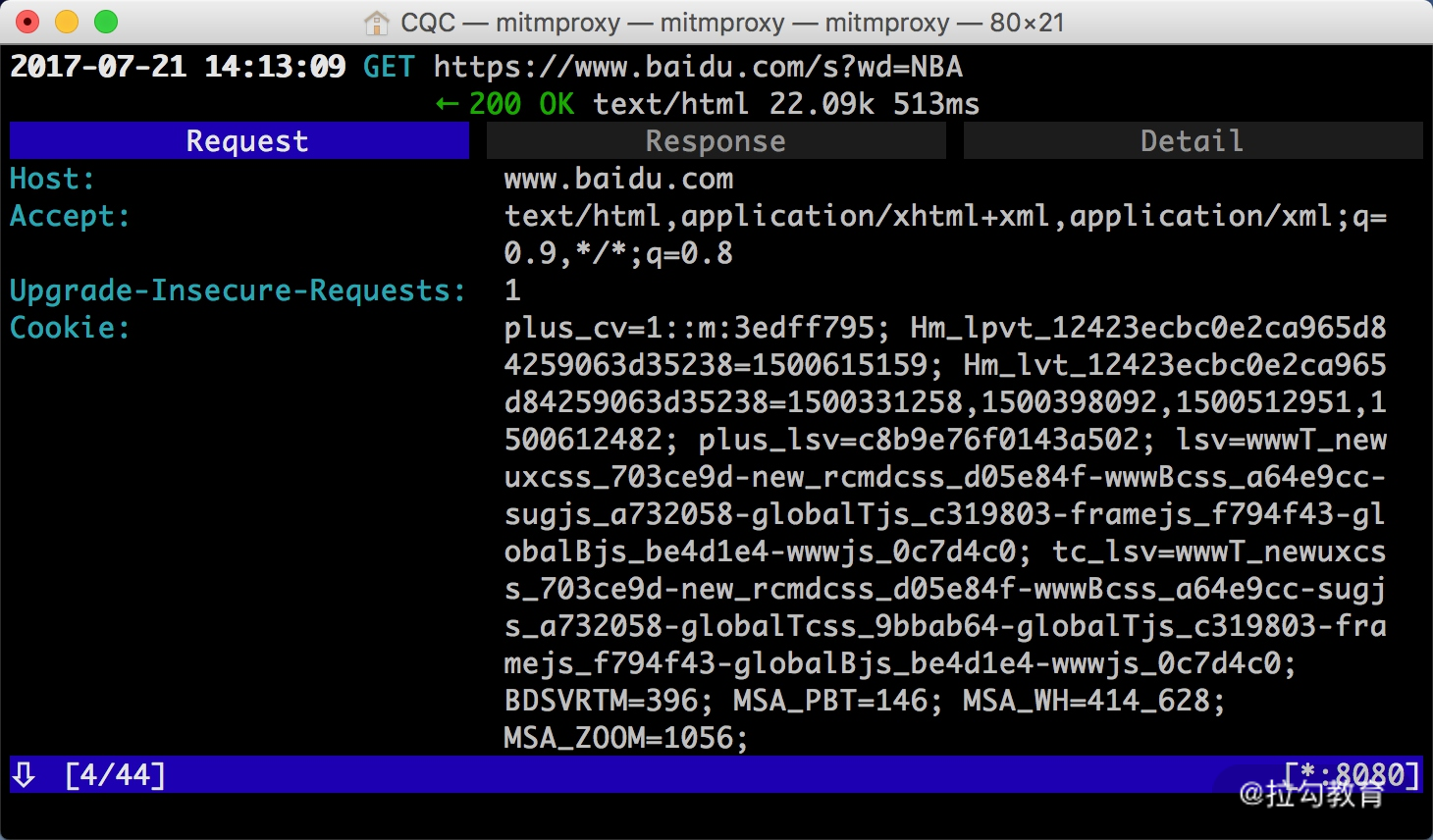
敲击 a 保存修改,敲击 r 重新发起修改后的请求,即可看到上方请求方式前面多了一个回旋箭头,这说明重新执行了修改后的请求。这时我们再观察响应体内容,即可看到搜索 NBA 的页面结果的源代码,如图所示。
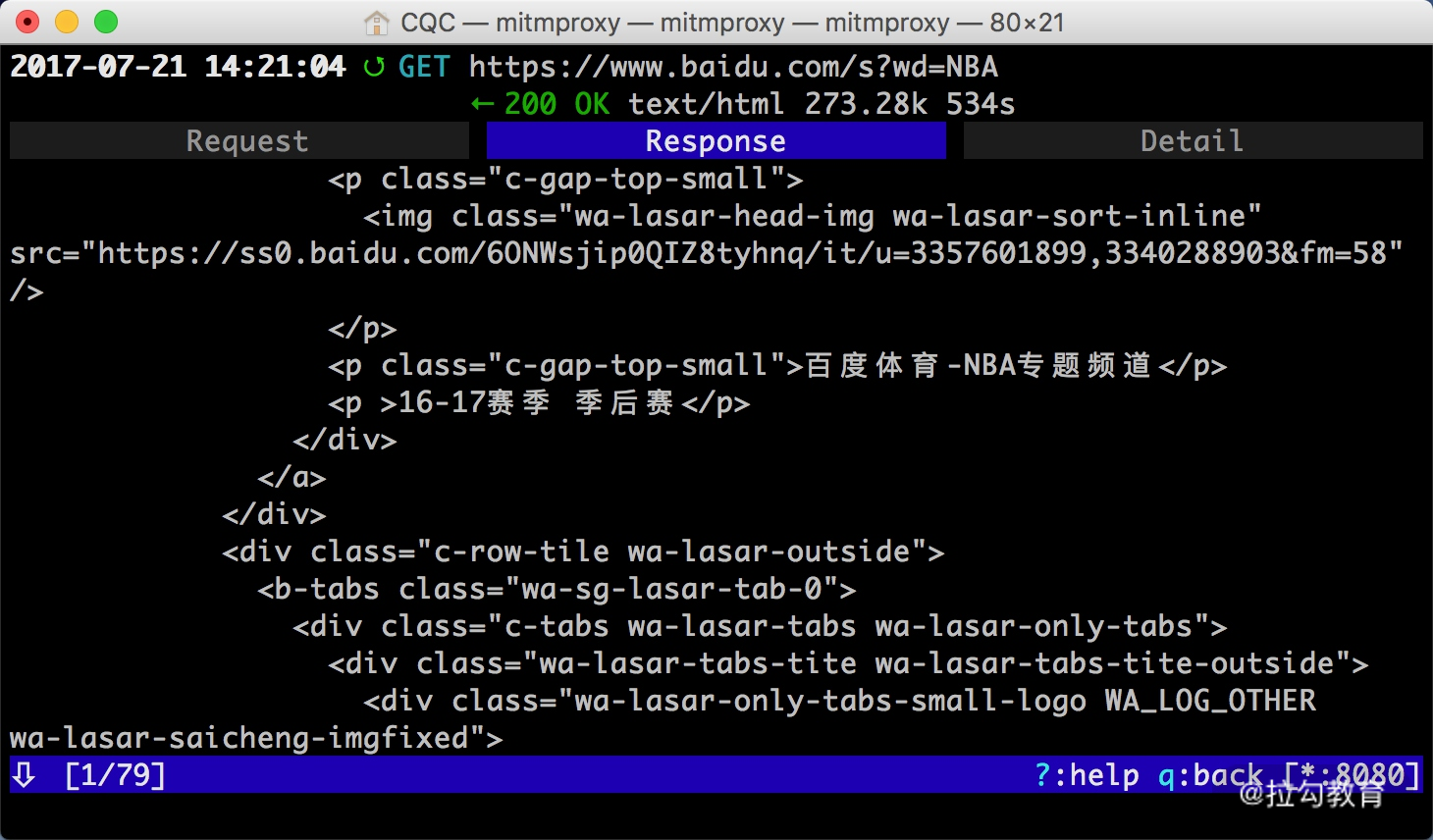
以上内容便是 mitmproxy 的简单用法。利用 mitmproxy,我们可以观察到手机上的所有请求,还可以对请求进行修改并重新发起。
Fiddler、Charles 也有这个功能,而且它们的图形界面操作更加方便。那么 mitmproxy 的优势何在?
mitmproxy 的强大之处体现在它的另一个工具 mitmdump,有了它我们可以直接对接 Python 对请求进行处理。下面我们来看看 mitmdump 的用法。
mitmdump 的使用
mitmdump 是 mitmproxy 的命令行接口,同时还可以对接 Python 对请求进行处理,这是相比 Fiddler、Charles 等工具更加方便的地方。有了它我们可以不用手动截获和分析 HTTP 请求和响应,只需写好请求和响应的处理逻辑即可。它还可以实现数据的解析、存储等工作,这些过程都可以通过 Python 实现。
实例引入
我们可以使用命令启动 mitmproxy,并把截获的数据保存到文件中,命令如下所示:
mitmdump -w outfile
其中 outfile 的名称任意,截获的数据都会被保存到此文件中。
还可以指定一个脚本来处理截获的数据,使用 - s 参数即可:
mitmdump -s script.py
这里指定了当前处理脚本为 script.py,它需要放置在当前命令执行的目录下。
我们可以在脚本里写入如下的代码:
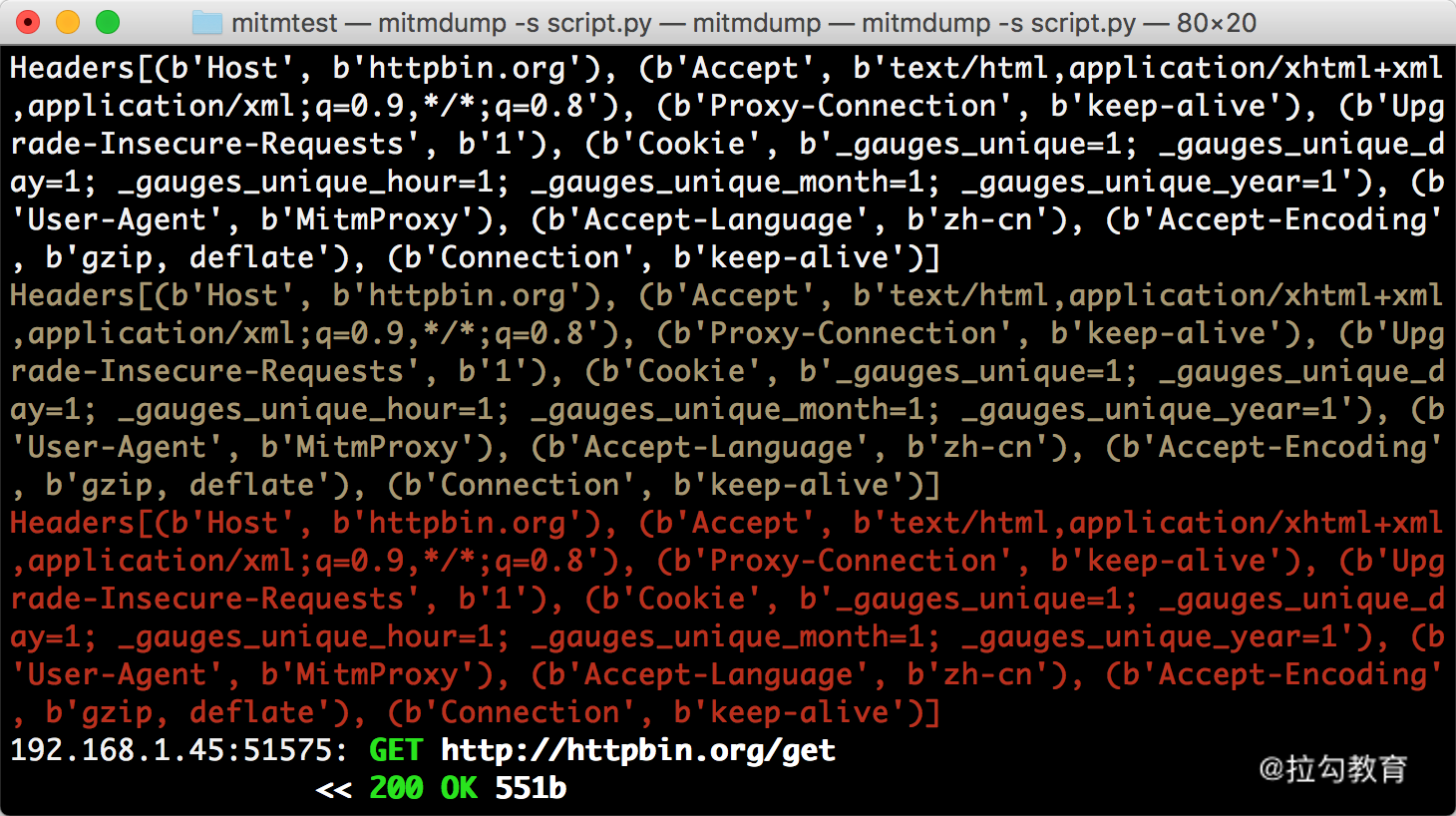
def request(flow):
flow.request.headers['User-Agent'] = 'MitmProxy'
print(flow.request.headers)
我们定义了一个 request 方法,参数为 flow,它其实是一个 HTTPFlow 对象,通过 request 属性即可获取到当前请求对象。然后打印输出了请求的请求头,将请求头的 User-Agent 修改成了 MitmProxy。
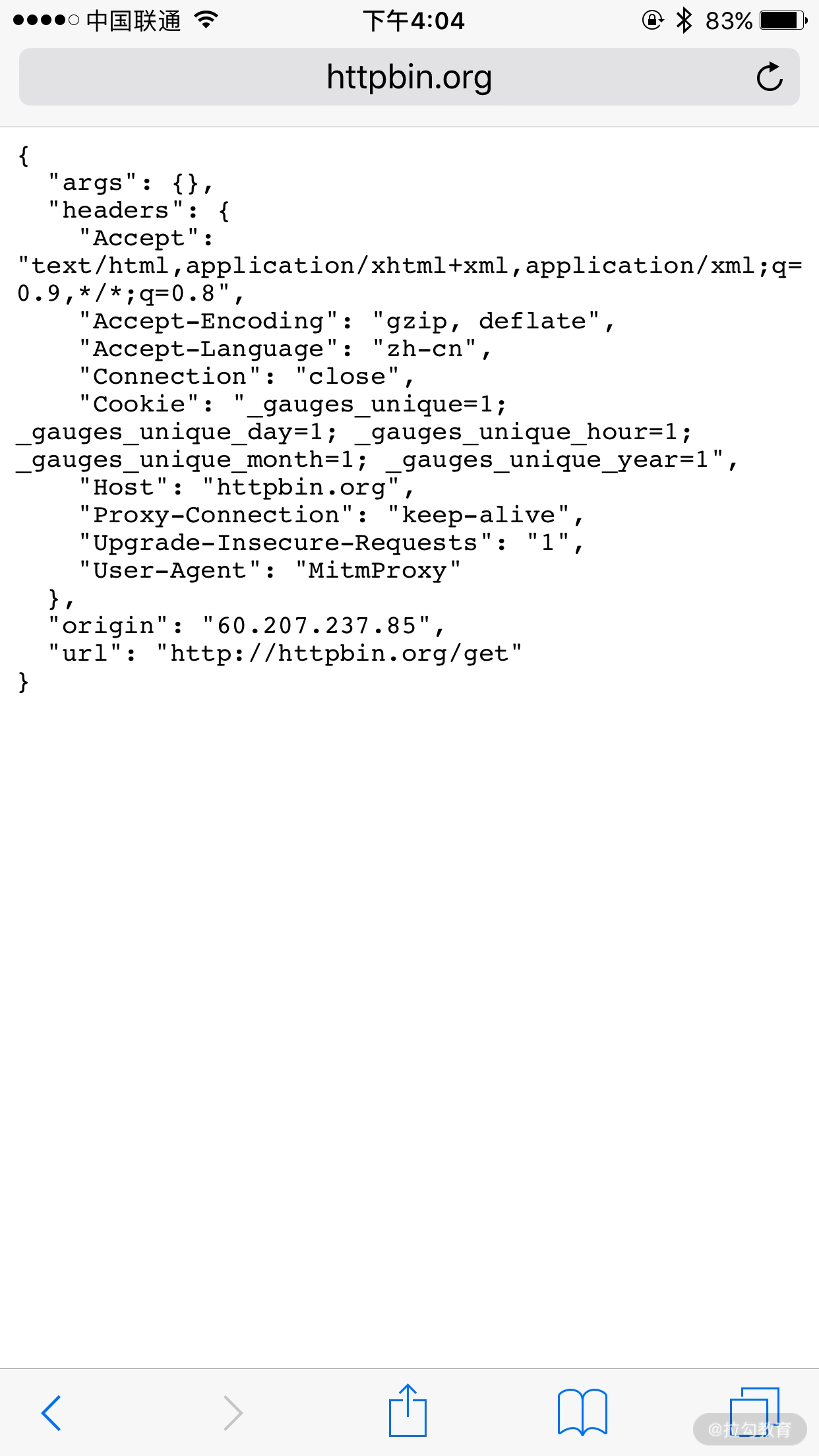
运行之后我们在手机端访问 http://httpbin.org/get,就可以看到有如下情况发生。
手机端的页面显示如图所示。
PC 端控制台输出如图所示。
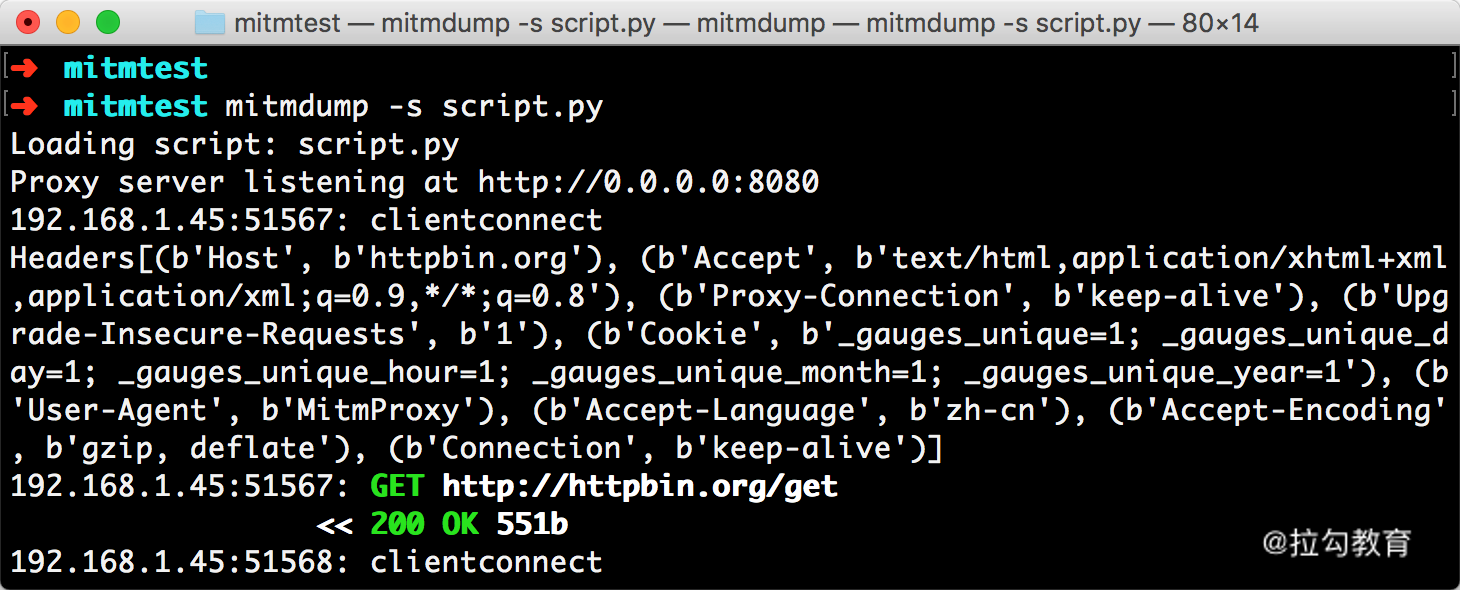
手机端返回结果的 Headers 实际上就是请求的 Headers,User-Agent 被修改成了 mitmproxy。PC 端控制台输出了修改后的 Headers 内容,其 User-Agent 的内容正是 mitmproxy。
所以,通过这三行代码我们就可以完成对请求的改写。print 方法输出结果可以呈现在 PC 端控制台上,可以方便地进行调试。
日志输出
mitmdump 提供了专门的日志输出功能,可以设定不同级别以不同颜色输出结果。我们把脚本修改成如下内容:
from mitmproxy import ctx
def request(flow):
flow.request.headers['User-Agent'] = 'MitmProxy'
ctx.log.info(str(flow.request.headers))
ctx.log.warn(str(flow.request.headers))
ctx.log.error(str(flow.request.headers))
这里调用了 ctx 模块,它有一个 log 功能,调用不同的输出方法就可以输出不同颜色的结果,以方便我们做调试。例如,info 方法输出的内容是白色的,warn 方法输出的内容是黄色的,error 方法输出的内容是红色的。运行结果如图所示。
不同的颜色对应不同级别的输出,我们可以将不同的结果合理划分级别输出,以更直观方便地查看调试信息。
Request
最开始我们实现了 request 方法并且对 Headers 进行了修改。下面我们来看看 Request 还有哪些常用的功能。我们先用一个实例来感受一下。
from mitmproxy import ctx
def request(flow):
request = flow.request
info = ctx.log.info
info(request.url)
info(str(request.headers))
info(str(request.cookies))
info(request.host)
info(request.method)
info(str(request.port))
info(request.scheme)
我们修改脚本,然后在手机上打开百度,即可看到 PC 端控制台输出了一系列的请求,在这里我们找到第一个请求。控制台打印输出了 Request 的一些常见属性,如 URL、Headers、Cookies、Host、Method、Scheme 等。输出结果如图所示。
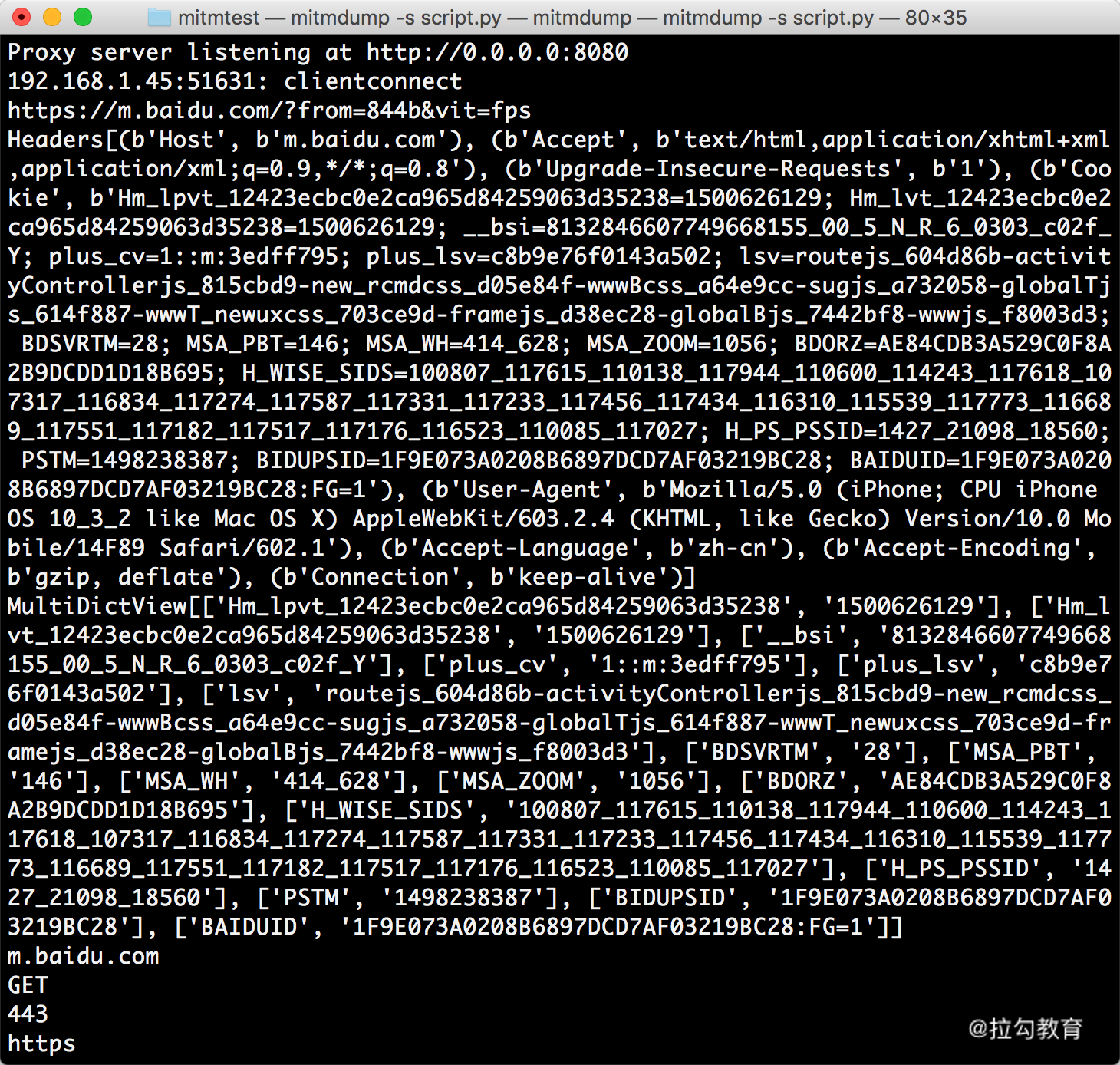
结果中分别输出了请求链接、请求头、请求 Cookies、请求 Host、请求方法、请求端口、请求协议这些内容。
同时我们还可以对任意属性进行修改,就像最初修改 Headers 一样,直接赋值即可。例如,这里将请求的 URL 修改一下,脚本修改如下所示:
def request(flow):
url = 'https://httpbin.org/get'
flow.request.url = url
手机端得到如下结果,如图所示。

比较有意思的是,浏览器最上方还是呈现百度的 URL,但是页面已经变成了 httpbin.org 的页面了。另外,Cookies 明显还是百度的 Cookies。我们只是用简单的脚本就成功把请求修改为其他的站点。通过这种方式修改和伪造请求就变得轻而易举。
通过这个实例我们知道,有时候 URL 虽然是正确的,但是内容并非正确。我们需要进一步提高自己的安全防范意识。
Request 还有很多属性,在此不再一一列举。更多属性可以参考:http://docs.mitmproxy.org/en/latest/scripting/api.html。
只要我们了解了基本用法,会很容易地获取和修改 Reqeust 的任意内容,比如可以用修改 Cookies、添加代理等方式来规避反爬。
Response
对于爬虫来说,我们更加关心的其实是响应的内容,因为 Response Body 才是爬取的结果。对于响应来说,mitmdump 也提供了对应的处理接口,就是 response 方法。下面我们用一个实例感受一下。
from mitmproxy import ctx
def response(flow):
response = flow.response
info = ctx.log.info
info(str(response.status_code))
info(str(response.headers))
info(str(response.cookies))
info(str(response.text))
将脚本修改为如上内容,然后手机访问:http://httpbin.org/get。
这里打印输出了响应的 status_code、headers、cookies、text 这几个属性,其中最主要的 text 属性就是网页的源代码。
PC 端控制台输出如图所示。
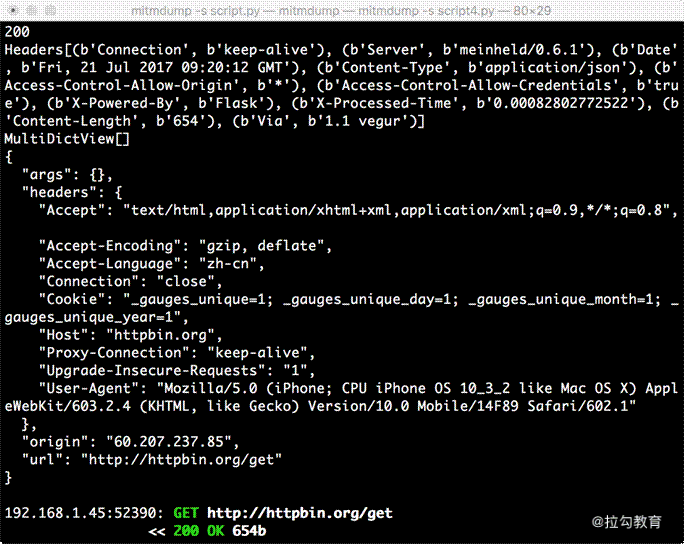
控制台输出了响应的状态码、响应头、Cookies、响应体这几部分内容。
我们可以通过 response 方法获取每个请求的响应内容。接下来再进行响应的信息提取和存储,我们就可以成功完成爬取了。
示例操作
下面我们来介绍一个 App 的爬取实现,示例 App 可以参见附件。
通过 Charles 抓包之后我们可以发现,其接口的 URL 中包含了一个 token 参数,如图所示。

而且这个 token 每次请求都是变化的,我们目前也观察不出它到底是怎么构造的。
那么我们如果想把抓包的这些结果保存下来,应该怎么办呢?显然就不好直接用程序来构造这些请求了,因为 token 的生成逻辑我们无从得知。这时候我们可以采取 mitmdump 实时处理的操作,只要能抓到包,那就可以把抓包的结果实时处理并保存下来。
首先我们写一个 mitmdump 脚本,还是和原来一样,保存为 spider.py 内容如下:
from mitmproxy import ctx
def response(flow):
response = flow.response
info = ctx.log.info
info(str(response.status_code))
info(str(response.headers))
info(str(response.cookies))
info(str(response.text))
然后启动一下脚本,命令如下:
mitmdump -s spider.py
设置好手机代理为 mitmdump 的地址。
这时候打开手机 App,会看到如下的界面,如图所示。

这时候我们再返回控制台,查看下 mitmdump 的输出,就会变成如下内容,如图所示。
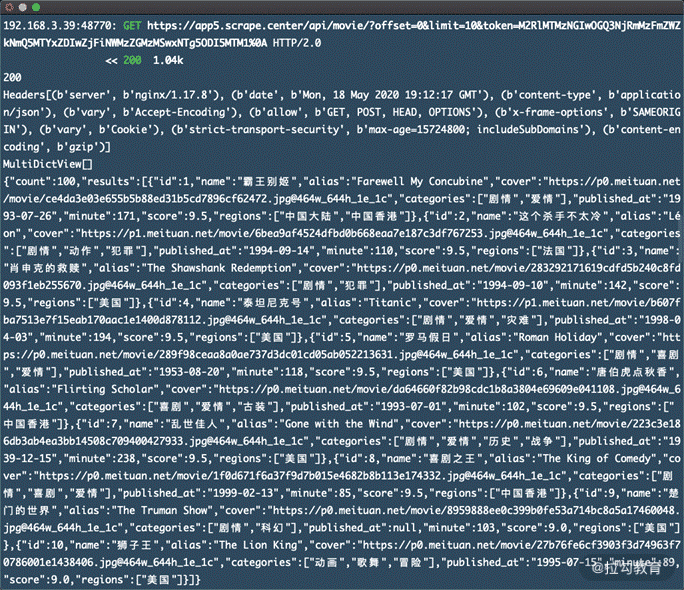
我们可以看到这里就输出来了抓包后的结果,最后的这个内容实际上就是接口的返回结果,我们直接将其输出到控制台上了。
经过一些分析我们可以很轻松得知一次请求就会获取 10 条电影的数据,我们可以对脚本进行下改写,对这个结果进行分析处理。比如我们可以遍历每一条电影数据,然后将其保存到本地,成为 JSON 文件。
脚本就可以改写如下:
from mitmproxy import ctx
import json
def response(flow):
response = flow.response
if response.status_code != 200:
return
data = json.loads(str(response.text))
for item in data.get('results'):
name = item.get('name')
with open(f'{name}.json', 'w', encoding='utf-8') as f:
f.write(json.dumps(item, indent=2, ensure_ascii=False))
这里我们首先对 response 的内容进行了解析,然后遍历了 results 字段的每个内容,然后获取其 name 字段当作文件输出的名称,最后输出保存成一个 JSON 文件。
这时候,我们再重新运行 mitmdump 和 App,就可以发现 mitmdump 的运行目录下就出现了好多 JSON 文件,这些 JSON 文件的内容就是抓包的电影数据的结果,如图所示。

我们打开其中一个结果,内容如下:
{
"id": 3,
"name": "肖申克的救赎",
"alias": "The Shawshank Redemption",
"cover": "https://p0.meituan.net/movie/283292171619cdfd5b240c8fd093f1eb255670.jpg@464w_644h_1e_1c",
"categories": [
"剧情",
"犯罪"
],
"published_at": "1994-09-10",
"minute": 142,
"score": 9.5,
"regions": [
"美国"
]
}
可以看到这就是我们在 Charles 中看到的返回结果中的一条电影数据的内容,我们通过 mitmdump 对接实时处理脚本实现了分析和保存。
以上便是 mitmproxy 和 mitmdump 的基本用法。
可见即可爬——Appium的使用
本课时我们主要学习如何使用 Appium。
Appium 是一个跨平台移动端自动化测试工具,可以非常便捷地为 iOS 和 Android 平台创建自动化测试用例。它可以模拟 App 内部的各种操作,如点击、滑动、文本输入等,只要我们手工操作的动作 Appium 都可以完成。在前面我们了解过 Selenium,它是一个网页端的自动化测试工具。Appium 实际上继承了 Selenium,Appium 也是利用 WebDriver 来实现 App 的自动化测试的。对 iOS 设备来说,Appium 使用 UIAutomation 来实现驱动。对于 Android 来说,它使用 UiAutomator 和 Selendroid 来实现驱动。
Appium 相当于一个服务器,我们可以向 Appium 发送一些操作指令,Appium 就会根据不同的指令对移动设备进行驱动,完成不同的动作。
对于爬虫来说,我们用 Selenium 来抓取 JavaScript 渲染的页面,可见即可爬。Appium 同样也可以,用 Appium 来做 App 爬虫不失为一个好的选择。
下面我们来了解 Appium 的基本使用方法。
本节目标
我们以 Android 平台的一个示例 apk 演示 Appium 启动和操作 App 的方法,主要目的是了解利用 Appium 进行自动化测试的流程以及相关 API 的用法。
准备工作
请确保 PC 已经安装好 Appium、Android 开发环境和 Python 版本的 Appium API,安装方法可以参考 https://cuiqingcai.com/5407.html。另外,Android 手机安装好示例安装包,下载地址为:https://app5.scrape.center/。
启动 APP
Appium 启动 App 的方式有两种:一种是用 Appium 内置的驱动器来打开 App,另一种是利用 Python 程序实现此操作。下面我们分别进行说明。
首先打开 Appium,启动界面如图所示。

直接点击 Start Server 按钮即可启动 Appium 的服务,相当于开启了一个 Appium 服务器。我们可以通过 Appium 内置的驱动或 Python 代码向 Appium 的服务器发送一系列操作指令,Appium 就会根据不同的指令对移动设备进行驱动,完成不同的动作。启动后运行界面如图所示。
Appium 运行之后正在监听 4723 端口。我们可以向此端口对应的服务接口发送操作指令,此页面就会显示这个过程的操作日志。
将 Android 手机通过数据线和运行 Appium 的 PC 相连,同时打开 USB 调试功能,确保 PC 可以连接到手机。
可以输入 adb 命令来测试连接情况,如下所示:
adb devices -l
如果出现如下类似结果,就说明 PC 已经正确连接手机。
List of devices attached
emulator-5554 device product:cancro model:MuMu device:x86 transport_id:231
第一个字段是设备的名称,就是后文需要用到的 deviceName 变量。我使用的是模拟器,所以此处名称为 emulator-5554。
如果提示找不到 adb 命令,请检查 Android 开发环境和环境变量是否配置成功。如果可以成功调用 adb 命令但不显示设备信息,请检查手机和 PC 的连接情况。
接下来用 Appium 内置的驱动器打开 App,点击 Appium 中的 Start New Session 按钮,如图所示。
这时会出现一个配置页面,如图所示。
需要配置启动 App 时的 Desired Capabilities 参数,它们分别是 platformName、deviceName、appPackage、appActivity。
- platformName:平台名称,需要区分是 Android 还是 iOS,此处填写 Android。
- deviceName:设备名称,是手机的具体类型。
- appPackage:App 程序包名。
- appActivity:入口 Activity 名,这里通常需要以
.开头。 - noReset:在打开 App 时不重置 Session,这里设置为 true。
在当前配置页面的左下角也有配置参数的相关说明,链接是 https://github.com/appium/appium/blob/master/docs/en/writing-running-appium/caps.md。
我们在 Appium 中加入上面 5 个配置,如图所示。
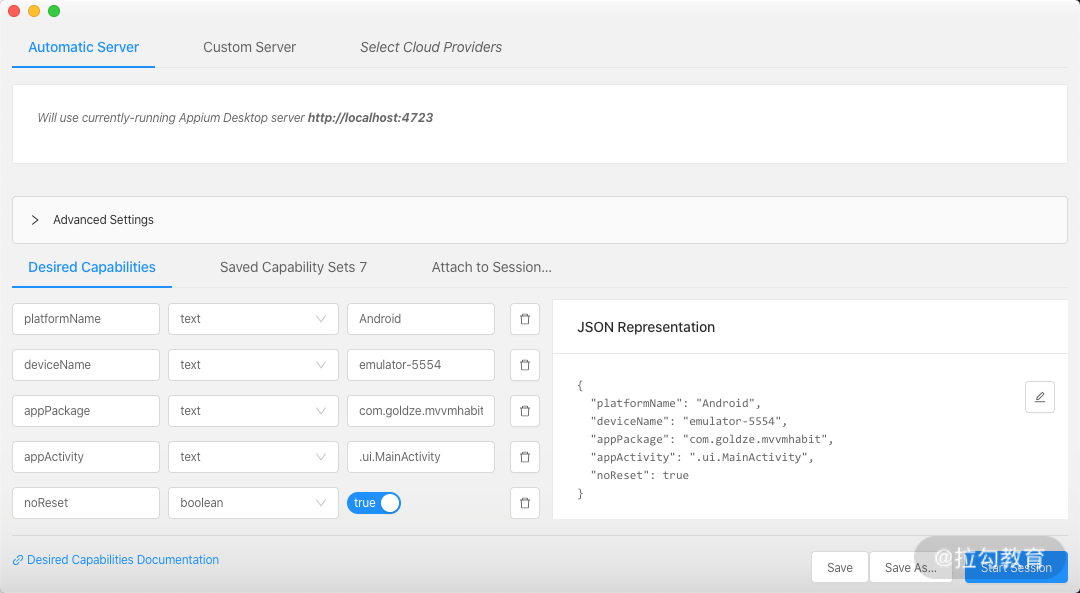
点击保存按钮,保存下来,我们以后可以继续使用这个配置。
点击右下角的 Start Session 按钮,即可启动 Android 手机上的 App 并进入启动页面。同时 PC 上会弹出一个调试窗口,从这个窗口我们可以预览当前手机页面,并可以查看页面的源码,如图所示。

点击左栏中屏幕的某个元素,如选中一个条目,它就会高亮显示。这时中间栏就显示了当前选中的元素对应的源代码,右栏则显示了该元素的基本信息,如元素的 id、class、text 等,以及可以执行的操作,如 Tap、Send Keys、Clear,如图所示。
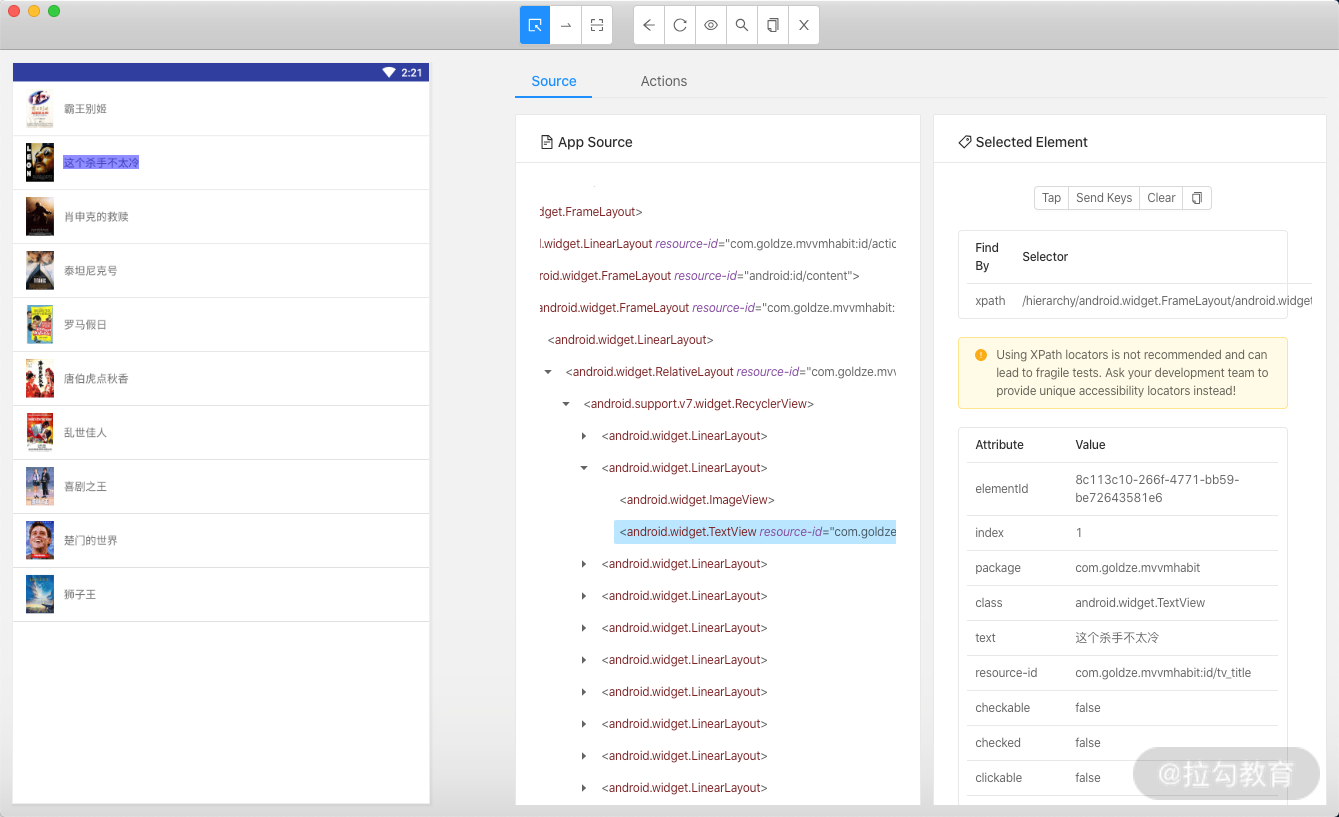
点击中间栏最上方的第三个录制按钮,Appium 会开始录制操作动作,这时我们在窗口中操作 App 的行为都会被记录下来,Recorder 处可以自动生成对应语言的代码。例如,我们点击录制按钮,然后选中其中一个条目,点击 Tap 操作,即模拟了按钮点击功能,这时手机和窗口的 App 都会跳转到对应的详情页面,同时中间栏会显示此动作对应的代码,如图所示。

我们可以在此页面点击不同的动作按钮,即可实现对 App 的控制,同时 Recorder 部分也可以生成对应的 Python 代码。
下面我们看看使用 Python 代码驱动 App 的方法。首先需要在代码中指定一个 Appium Server,而这个 Server 在刚才打开 Appium 的时候就已经开启了,是在 4723 端口上运行的,配置如下所示:
server = 'http://localhost:4723/wd/hub'
用字典来配置 Desired Capabilities 参数,代码如下所示:
desired_caps = {
'platformName': 'Android',
'deviceName': 'emulator-5554',
'appPackage': 'com.goldze.mvvmhabit',
'appActivity': '.ui.MainActivity'
}
新建一个 Session,这类似点击 Appium 内置驱动的 Start Session 按钮相同的功能,代码实现如下所示:
from appium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
driver = webdriver.Remote(server, desired_caps)
配置完成后运行,就可以启动 App了。但是现在仅仅是可以启动 App,还没有做任何动作。
再用代码来模拟刚才演示的两个动作:点击某个条目,然后返回。
看看刚才 Appium 内置驱动器内的 Recorder 录制生成的 Python 代码,自动生成的代码非常累赘,例如点击某个条目然后返回的代码如下所示:
el1 = driver.find_element_by_xpath("/hierarchy/android.widget.FrameLayout/android.widget.LinearLayout/android.widget.FrameLayout/android.widget.LinearLayout/android.widget.FrameLayout/android.widget.FrameLayout/android.widget.LinearLayout/android.widget.RelativeLayout/android.support.v7.widget.RecyclerView/android.widget.LinearLayout[2]")
el1.click()
driver.back()
我们稍微整理修改一下,然后再加上获取文本的操作,完整的代码如下所示:
from appium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
server = 'http://localhost:4723/wd/hub'
desired_caps = {
'platformName': 'Android',
'deviceName': 'emulator-5554',
'appPackage': 'com.goldze.mvvmhabit',
'appActivity': '.ui.MainActivity',
'adbExecTimeout': 200000,
}
driver = webdriver.Remote(server, desired_caps)
wait = WebDriverWait(driver, 1000)
item_element = wait.until(EC.presence_of_element_located(
(By.XPATH, '//android.support.v7.widget.RecyclerView/android.widget.LinearLayout[2]')))
item_title_element = item_element.find_element_by_xpath('//android.widget.TextView')
text = item_title_element.text
print('text', text)
item_element.click()
driver.back()
运行此代码,这时即可观察到手机上首先弹出了 App,然后模拟点击了其中一个条目,然后返回了主页。同时还输出了提取到的节点内的文本。
这样我们就成功使用 Python 代码实现了 App 的操作。
API
接下来看看使用代码如何操作 App、总结相关 API 的用法。这里使用的 Python 库为 AppiumPythonClient,其 GitHub 地址为 https://github.com/appium/python-client,此库继承自 Selenium,使用方法与 Selenium 有很多共同之处。
初始化
需要配置 Desired Capabilities 参数,完整的配置说明可以参考 https://github.com/appium/appium/blob/master/docs/en/writing-running-appium/caps.md,一般来说我们配置几个基本参数即可:
from appium import webdriver
server = 'http://localhost:4723/wd/hub'
desired_caps = {
'platformName': 'Android',
'deviceName': 'emulator-5554',
'appPackage': 'com.goldze.mvvmhabit',
'appActivity': '.ui.MainActivity'
}
driver = webdriver.Remote(server, desired_caps)
这里配置了启动 App 的 Desired Capabilities,这样 Appium 就会自动查找手机上的包名和入口类,然后将其启动。包名和入口类的名称可以在安装包中的 AndroidManifest.xml 文件获取。
如果要打开的 App 没有事先在手机上安装,我们可以直接指定 App 参数为安装包所在路径,这样程序启动时就会自动向手机安装并启动 App,如下所示:
from appium import webdriver
server = 'http://localhost:4723/wd/hub'
desired_caps = {
'platformName': 'Android',
'deviceName': 'emulator-5554',
'app': './app.apk'
}
driver = webdriver.Remote(server, desired_caps)
程序启动的时候就会寻找 PC 当前路径下的 apk 安装包,然后将其安装到手机中并启动。
查找元素
我们可以使用 Selenium 中通用的查找方法来实现元素的查找,如下所示:
el = driver.find_element_by_id('com.package.name:id/path')
在 Selenium 中,其他查找元素的方法同样适用,在此不再赘述。
在 Android 平台上,我们还可以使用 UIAutomator 来进行元素选择,如下所示:
el = self.driver.find_element_by_android_uiautomator('new UiSelector().description("Animation")')
els = self.driver.find_elements_by_android_uiautomator('new UiSelector().clickable(true)')
在 iOS 平台上,我们可以使用 UIAutomation 来进行元素选择,如下所示:
el = self.driver.find_element_by_ios_uiautomation('.elements()[0]')
els = self.driver.find_elements_by_ios_uiautomation('.elements()')
还可以使用 iOS Predicates 来进行元素选择,如下所示:
el = self.driver.find_element_by_ios_predicate('wdName == "Buttons"')
els = self.driver.find_elements_by_ios_predicate('wdValue == "SearchBar" AND isWDDivisible == 1')
也可以使用 iOS Class Chain 来进行选择,如下所示:
el = self.driver.find_element_by_ios_class_chain('XCUIElementTypeWindow/XCUIElementTypeButton[3]')
els = self.driver.find_elements_by_ios_class_chain('XCUIElementTypeWindow/XCUIElementTypeButton')
但是此种方法只适用于 XCUITest 驱动,具体可以参考:https://github.com/appium/appium-xcuitest-driver。
点击
点击可以使用 tap 方法,该方法可以模拟手指点击(最多五个手指),可设置按时长短(毫秒),代码如下所示:
tap(self, positions, duration=None)
参数:
- positions,点击的位置组成的列表。
- duration,点击持续时间。
实例如下:
driver.tap([(100, 20), (100, 60), (100, 100)], 500)
这样就可以模拟点击屏幕的某几个点。
另外对于某个元素如按钮来说,我们可以直接调用 cilck方法实现模拟点击,实例如下所示:
button = find_element_by_id('com.tencent.mm:id/btn')
button.click()
这样获取元素之后,然后调用 click方法即可实现该元素的模拟点击。
屏幕拖动
可以使用 scroll 方法模拟屏幕滚动,用法如下所示:
scroll(self, origin_el, destination_el)
可以实现从元素 origin_el 滚动至元素 destination_el。
参数:
- original_el,被操作的元素。
- destination_el,目标元素。
实例如下:
driver.scroll(el1,el2)
我们还可以使用 swipe 模拟从 A 点滑动到 B 点,用法如下:
swipe(self, start_x, start_y, end_x, end_y, duration=None)
参数:
- start_x,开始位置的横坐标。
- start_y,开始位置的纵坐标。
- end_x,终止位置的横坐标。
- end_y,终止位置的纵坐标。
- duration,持续时间,毫秒。
实例如下:
driver.swipe(100, 100, 100, 400, 5000)
这样可以实现在 5s 由 (100,100) 滑动到 (100,400)。
另外可以使用 flick 方法模拟从 A 点快速滑动到 B 点,用法如下:
flick(self, start_x, start_y, end_x, end_y)
参数:
- start_x,开始位置的横坐标。
- start_y,开始位置的纵坐标。
- end_x,终止位置的横坐标。
- end_y,终止位置的纵坐标。
实例如下:
driver.flick(100, 100, 100, 400)
拖拽
可以使用 drag_and_drop 实现某个元素拖动到另一个目标元素上。
用法如下:
drag_and_drop(self, origin_el, destination_el)
可以实现元素 origin_el 拖拽至元素 destination_el。
参数:
- original_el,被拖拽的元素。
- destination_el,目标元素。
实例如下所示:
driver.drag_and_drop(el1, el2)
文本输入
可以使用 set_text 方法实现文本输入,如下所示:
el = find_element_by_id('com.tencent.mm:id/cjk')
el.set_text('Hello')
我们选中一个文本框元素之后,然后调用 set_text 方法即可实现文本输入。
动作链
与 Selenium 中的 ActionChains 类似,Appium 中的 TouchAction 可支持的方法有 tap、press、long_press、release、move_to、wait、cancel 等,实例如下所示:
el = self.driver.find_element_by_accessibility_id('Animation')
action = TouchAction(self.driver)
action.tap(el).perform()
首先选中一个元素,然后利用 TouchAction 实现点击操作。
如果想要实现拖动操作,可以用如下方式:
els = self.driver.find_elements_by_class_name('listView')
a1 = TouchAction()
a1.press(els[0]).move_to(x=10, y=0).move_to(x=10, y=-75).move_to(x=10, y=-600).release()
a2 = TouchAction()
a2.press(els[1]).move_to(x=10, y=10).move_to(x=10, y=-300).move_to(x=10, y=-600).release()
利用以上 API,我们就可以完成绝大部分操作。
更多的 API 操作可以参考 https://testerhome.com/topics/3711。
结语
本节中,我们主要了解了 Appium 的操作 App 的基本用法以及常用 API 的用法。利用它我们就可以对 App 进行可视化操作并像 Selenium 一样提取页面信息了。
更好用的自动化工具airtest的使用
在上一节课我们了解了 Appium 的用法,利用 Appium 可以方便地完成 App 的自动化控制,但在使用过程中或多或少还会有些不方便的地方,比如响应速度慢,提供的 API 功能有限等。
本课时我们再介绍另外一个更好用的自动化测试工具,叫作 airtest,它提供了一些更好用的 API,同时提供了非常强大的 IDE,开发效率和响应速度相比 Appium 也有提升。
Airtest 概况
AirtestProject 是由网易游戏推出的一款自动化测试框架,项目构成如下。
- Airtest:是一个跨平台的、基于图像识别的 UI 自动化测试框架,适用于游戏和 App,支持平台有 Windows、Android 和 iOS,基于 Python 实现。
- Poco:是一款基于 UI 控件识别的自动化测试框架,目前支持 Unity3D/cocos2dx/Android 原生 App/iOS 原生 App/微信小程序,也可以在其他引擎中自行接入 poco-sdk 来使用,同样是基于 Python 实现的。
- AirtestIDE:提供了一个跨平台的 UI 自动化测试编辑器,内置了 Airtest 和 Poco 的相关插件功能,能够使用它快速简单地编写
Airtest和Poco代码。 - AirLab:真机自动化云测试平台,目前提供了 TOP100 手机兼容性测试、海外云真机兼容性测试等服务。
- 私有化手机集群技术方案:从硬件到软件,提供了企业内部私有化手机集群的解决方案。
总之,Airtest 建立了一个比较完善的自动化测试解决方案,利用 Airtest 我们自然就能实现 App 内可见即可爬的爬取。
本节内容
本节我们会简单介绍 Airtest IDE 的基本使用,同时介绍一些 Airtest 和 Poco 的基本 API 的用法,最后我们以一个实例来实现 App 的模拟和爬取。
这里使用的平台还是安卓平台,请确保现在你准备好了一台安卓的手机或模拟器。
Airtest 的安装
在 Airtest 的官方文档中已经详细介绍了 Airtest 的安装方式,包括 AirtestIDE、Airtest Python 库、Poco Python 库。
如果我们只使用 AirtestIDE 来实现自动化模拟和数据爬取的话是没问题的,因为它里面已经内置了 Python、 Airtest Python 库、Poco Python 库。AirtestIDE 提供了非常便捷的可视化点选和代码生成等功能,你没有任何 Python 代码基础的话,仅仅使用 AirtestIDE 就可以完成 App 的自动化控制和数据的爬取了。但是对于大量数据的爬取和页面跳转控制这样的场景来说,如果仅仅依靠可视化点选和自动生成的代码来进行 App 的自动化控制,其实是不灵活的。
进一步地,如果我们再加上一些代码逻辑的话,比如一些流程控制、循环控制语句,我们就可以实现批量数据的爬取了,这时候我们就需要依赖于 Airtest、Poco 以及一些自定义逻辑和第三方库来实现了。
所以,这里建议同时安装 AirtestIDE、Airtest、Poco。
AirtestIDE 的安装方式参见链接:https://airtest.doc.io.netease.com/tutorial/1_quick_start_guide/。
Airtest 的安装命令如下:
pip3 install airtest
Poco 的安装命令如下:
pip3 install pocoui
安装完成之后,可以在 AirtestIDE 中把 Python 的解释器更换成系统的 Python 解释器,而不再是 AirtestIDE 内置的 Python 解释器,修改方法参见 https://airtest.doc.io.netease.com/IDEdocs/run_script/1_useCommand_runScript/。
AirtestIDE 体验
在这里我以一台安卓手机来演示 AirtestIDE 的使用。
首先参考 https://airtest.doc.io.netease.com/tutorial/1_quick_start_guide/#_4 来完成手机的连接,确保使用 adb 可以正常获取到手机的相关信息,如:
adb devices
如果能正常输出手机相关信息,则证明连接成功,示例如下:
adb server version (40) doesn't match this client (41); killing...
* daemon started successfully
List of devices attached
6T9DYHNNDMUC8LBI device
这里就能看到我的设备名称为 6T9DYHNNDMUC8LBI。
然后启动 AirtestIDE,新建一个脚本,界面如图所示:
这时候在右侧我们可以看到已经连接的设备,如果没有出现,可以查看 https://airtest.doc.io.netease.com/IDEdocs/device_connection/2_android_faq/ 来排查一些问题。
接下来我们点击设备列表右侧的 connect 按钮,就可以在 IDE 中看到手机的屏幕了,如图所示。
另外可以观察到,整个 IDE 被分成了三列。
- 左侧上半部分:Airtest 辅助窗,可以通过一些点选操作实现基于图像识别的自动化配置。
- 左侧下半部分:Poco 辅助窗,可以通过一些点选操作实现基于 UI 控件识别的自动化配置。
- 中间上半部分:代码区域,可以通过 Airtest 辅助窗和 Poco 辅助窗自动生成代码,同时也可以自己编写代码,代码是基于 Python 语言的。
- 中间下半部分:日志区域,会输出运行时、调试时的一些日志。
- 右侧部分:手机的屏幕。
在这里我们可以通过鼠标直接点触右侧部分的手机屏幕,可以发现真机或模拟器的屏幕也会跟着变化,而且响应速度非常快。
接下来我们来实验一下 Airtest 辅助器。Airtest 可以基于图像识别来实现自动化控制,我们来体验一下。
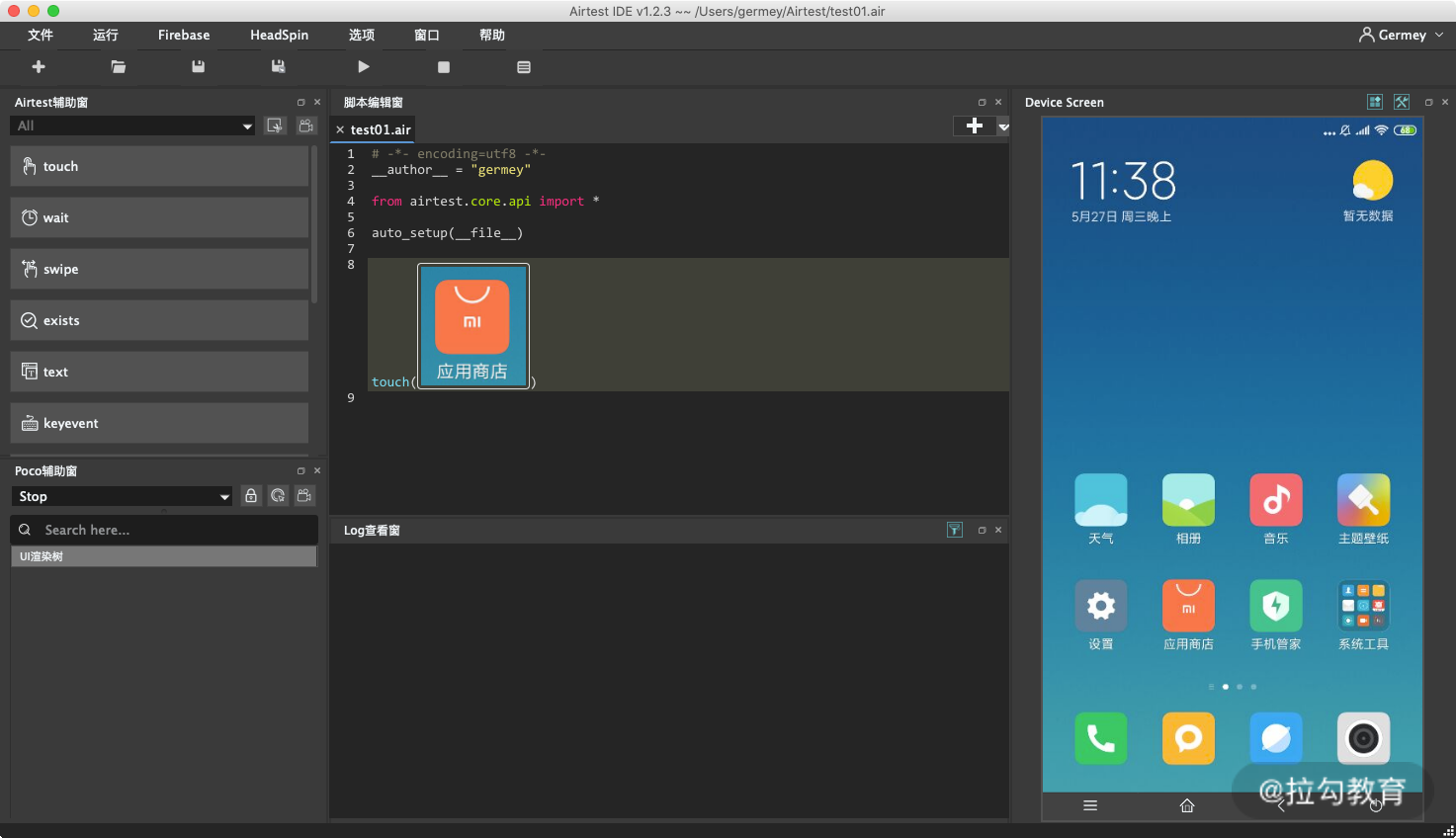
比如在这里我先点击左侧的 touch 按钮,其含义就是点击。这时候 AirtestIDE 会提示我们在右侧屏幕截图,比如这里我们截取“应用商店”,这时候我们可以发现 AirtestIDE 中便会出现了一行代码。代码的内容为 touch,然后其参数就是一张可视化的图片。
然后我们再选择 wait,其含义就是等待某个内容加载出来,同样地进行屏幕截图,如截取菜单栏的一部分,证明已经成功进入了应用商店首页。
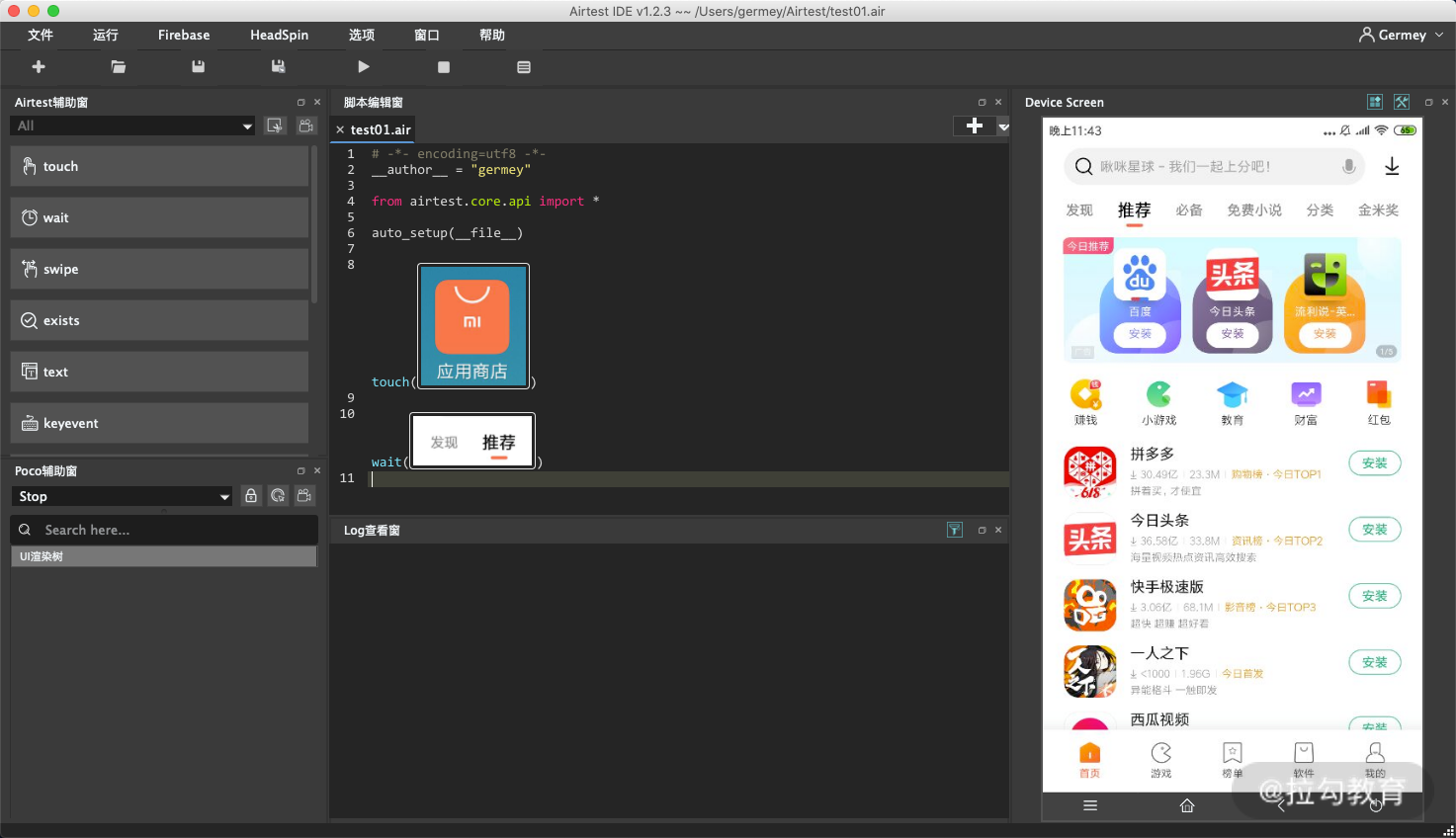
再然后我们点击 swipe,其含义就是滑动屏幕,这时候 AirtestIDE 会提示我们先选择一个区域,再选择滑动到目标位置,如图所示。
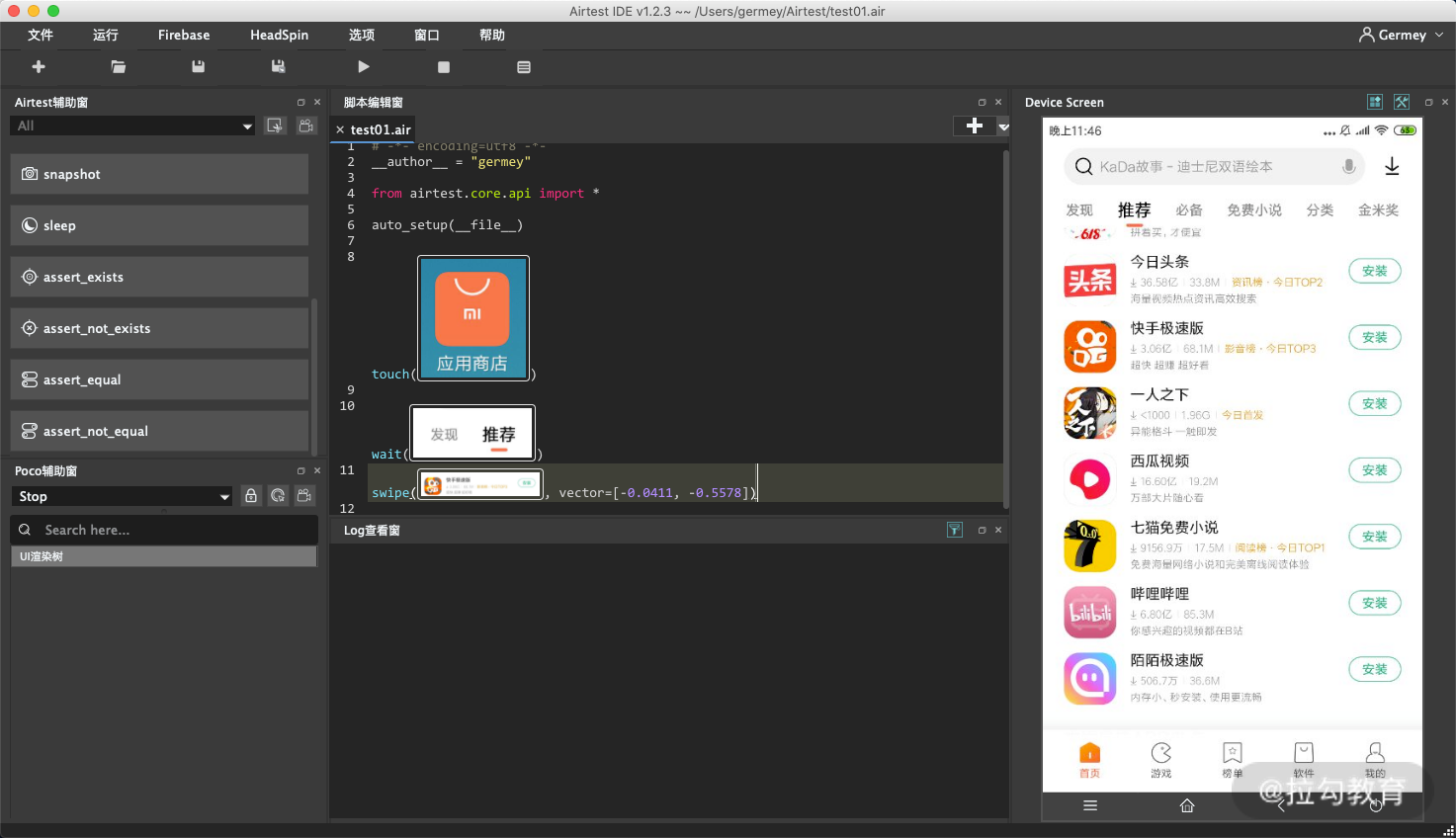
这里我们就通过一些可视化的配置完成了自动化的配置。
最后我们在代码的开头部分再加一个 keyevent,代表一些键盘事件,内容如下:
keyevent("HOME")
结果如下:
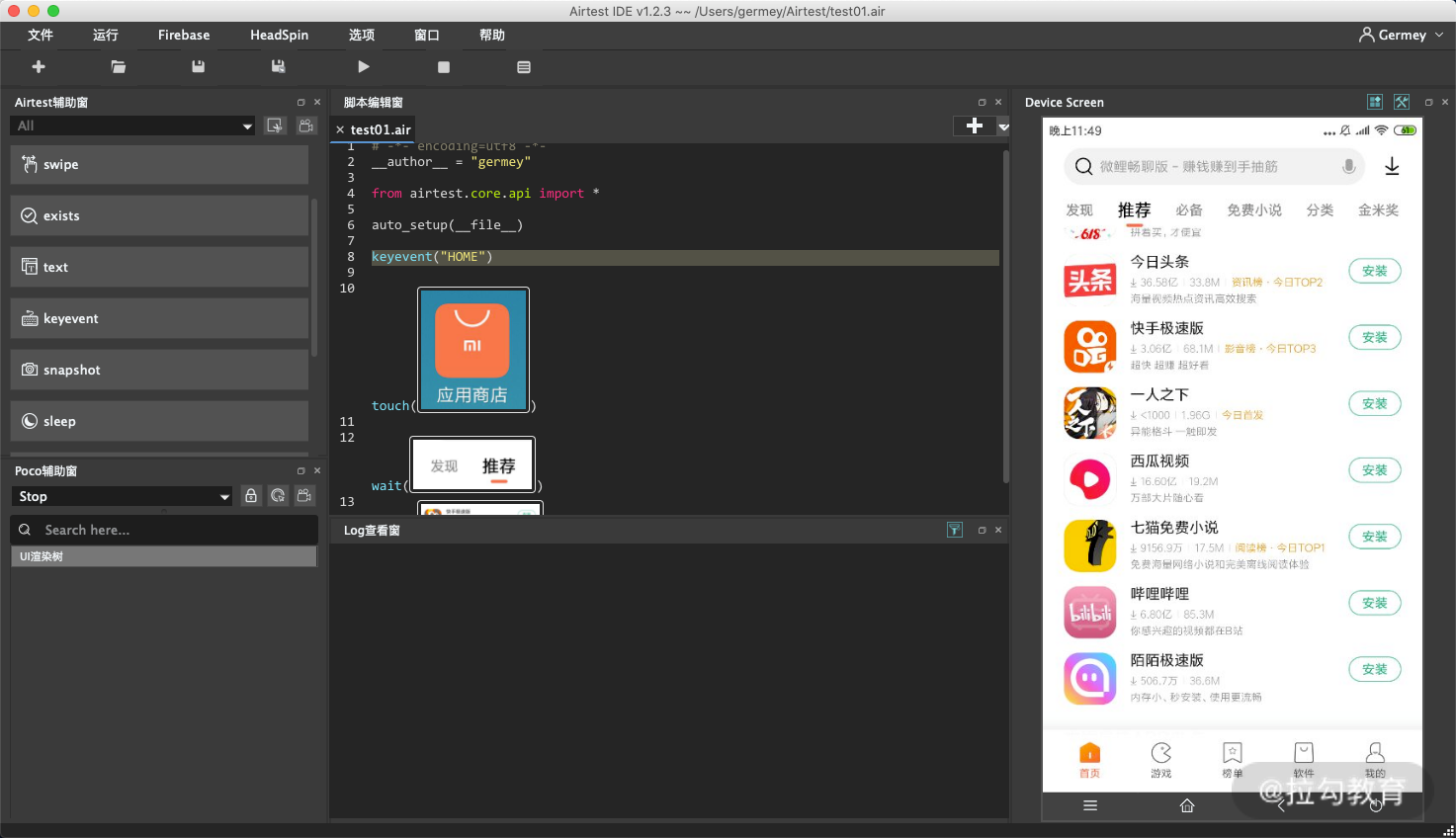
这样我们就能实现这样的自动化控制流程了:
- 进入手机首页;
- 点击“应用商店”;
- 等待菜单内容加载出来;
- 向上滑动屏幕。
怎么样,是不是很简单。如果你的手机内容和本示例不一样的话,可以灵活更换其中的配置内容。
这时候,我们点击运行按钮,即可发现 Airtest 便可以自动驱动手机完成一些自动化的操作了。以上便是 Airtest 提供的基于图像识别技术的自动化控制。
但很多情况下图像识别的速度可能不是很快,另外图像的截图也不一定是精确的,而且存在一定的风险,比如有的图像更换了,那可能就会影响自动化测试的流程。另外对于大批量的数据采集和循环控制,图像识别也不是一个好的方案。
所以,这里再介绍一个基于 Poco 的 UI 控件自动化控制,其实说白了就是基于一些 UI 名称和属性的选择器的自动化控制,有点类似于 Appium、Selenium 中的 XPath。
这里我们先点击左侧 Poco 辅助窗的下拉菜单,更换到 Android,这时候 AirtestIDE 会提示我们更新代码,点击确定之后可以发现其自动为我们添加了如下代码:
from poco.drivers.android.uiautomation import AndroidUiautomationPoco
poco = AndroidUiautomationPoco(use_airtest_input=True, screenshot_each_action=False)
这其实就是导入了 Poco 的 AndroidUiautomationPoco 模块,然后声明了一个 poco 对象。
接下来我们就可以通过 poco 对象来选择一些内容了。
我们此时点击左侧的控件树,可以发现右侧的手机屏幕就有对应的高亮显示,如图所示。这就有点像浏览器开发者工具里面选取网页源代码,这里的 UI 控件树就类似于网页里面的 HTML DOM 树。
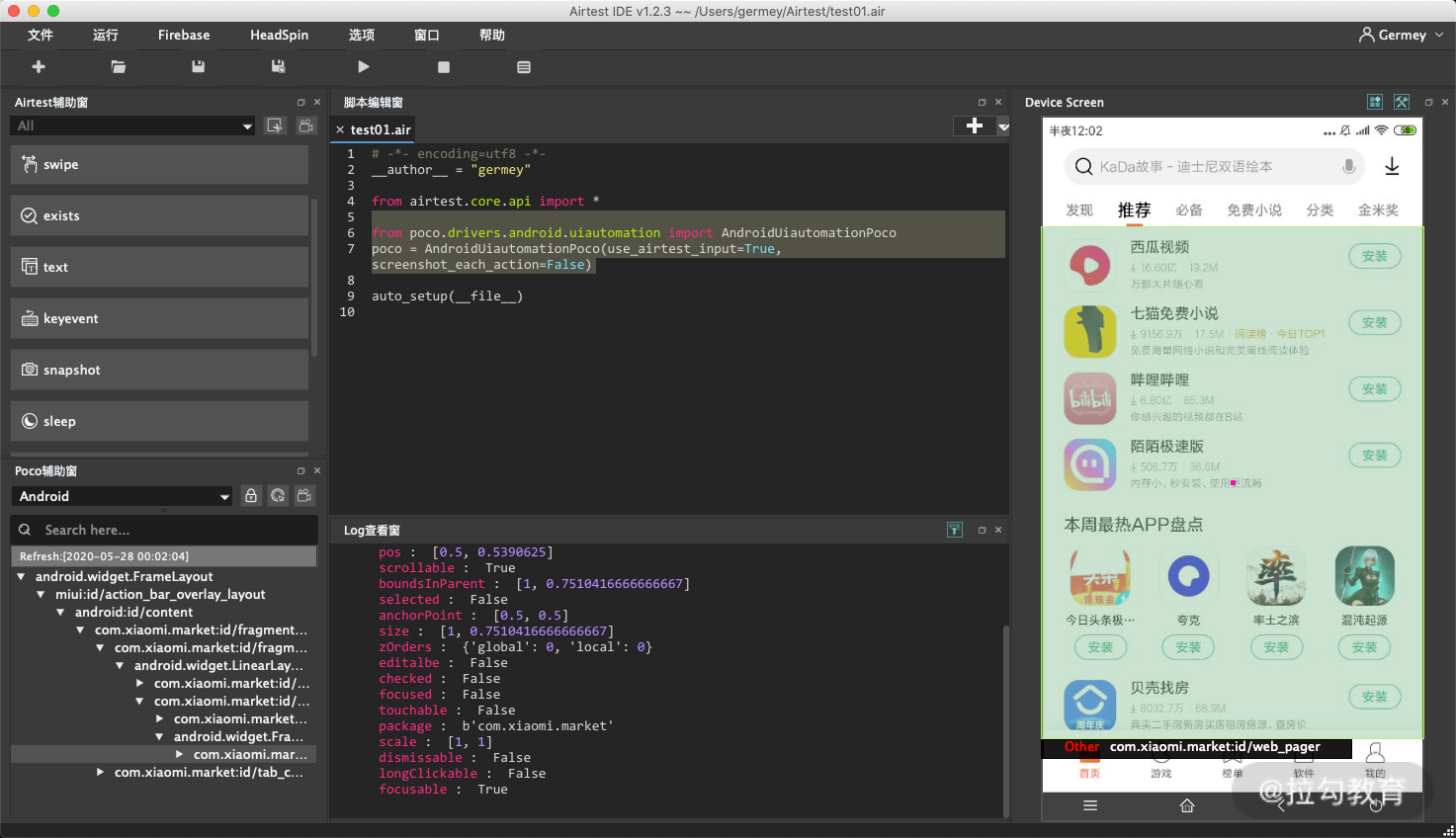
接着我们点击辅助窗的右上角的录制按钮,如图所示。
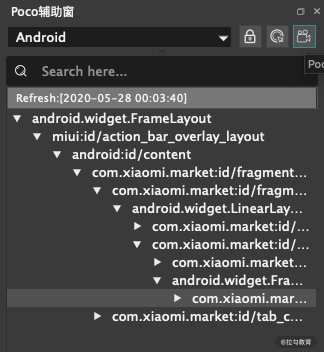
录制之后可以在右侧屏幕进行一些点选或滑动的一些操作,在代码区域就可以生成一些操作代码,如图所示。
这里也类似 Appium 里面录制并生成操作代码的过程。
比如这里经过我的一些操作,代码区域自动生成了如下代码:
poco("com.xiaomi.market:id/inner_webview").swipe([0.013, -0.2461])
poco("com.miui.home:id/workspace").offspring("应用商店").offspring("com.miui.home:id/icon_icon").click()
poco("com.miui.systemAdSolution:id/view_skip").click()
poco("com.xiaomi.market:id/inner_webview").swipe([0.0391, -0.3545])
poco("com.xiaomi.market:id/inner_webview").swipe([0.0807, -0.5098])
poco("com.xiaomi.market:id/inner_webview").swipe([0.0156, -0.3516])
poco("com.xiaomi.market:id/fragment_root_view").child("com.xiaomi.market:id/fragment_container").child("android.widget.LinearLayout").offspring("小米应用商店").child("android.view.View").child("android.widget.ListView")[1].child("android.view.View")[3].child("android.view.View")[0].child("android.view.View").child("android.view.View")[1].child("android.view.View")[1].click()
poco("com.xiaomi.market:id/top_bar_back_iv").click()
通过这些内容我们可以观察到有这样的规律:
poco 对象可以直接接收一个控件树选择器,然后就可以调用一些操作方法,如 swipe、click 等等完成一些操作。
另外 poco 对象还支持链式选择,如 poco 对象的调用返回结果后面紧跟了 child 方法、offspring 的方法的调用,同时还支持索引选择,其最终的返回结果依然可以调用一些操作方法,如 swipe、click 等完成一些操作。
所以,这里我们就可以初步得出如下结论:
- poco 对象支持通过传入一些 UI Path 来进行元素选择,最终会返回一个可操作对象。
- poco 对象返回的可操作对象支持链式选择,如选择其子孙节点、兄弟节点、父节点等等。
但其实可以观察到现在利用录制的方式自动生成的代码并不太规范,也不太灵活。既然已经是纯编程方式实现自动化控制,那么我们有必要来了解下 Poco 的一些具体用法。
Poco
Poco 是一款基于 UI 控件识别的自动化测试框架,目前支持 Unity3D/cocos2dx/Android 原生 App/iOS 原生 App/微信小程序,同样是基于 Python 实现的。
其 GitHub 地址为:https://github.com/AirtestProject/Poco。
首先可以看下 Poco 这个对象,其 API 为:
class Poco(agent, **options)
一般来说我们会使用它的子类,比如安卓就会使用 AndroidUiautomationPoco 来声明一个 poco 对象,这个就相当于手机操作的句柄,类似于是 Selenium 中的 webdriver 对象,通过调用它的一些选择器和操作方法就可以完成手机的一些操作。
用法类似如下:
poco = Poco(...)
close_btn = poco('close', type='Button')
这里我们可以发现,poco 本身就是一个对象,但它是可以直接调用并传入 UI 控件的名称的,这归根结底是因为其实现了一个 __call__ 方法,实现如下:
def __call__(self, name=None, **kw):
if not name and len(kw) == 0:
warnings.warn("Wildcard selector may cause performance trouble. Please give at least one condition to shrink range of results")
return UIObjectProxy(self, name, **kw)
可以看到其就是返回了一个 UIObjectProxy 对象,这个就对应页面中的某个 UI 组件,如一个输入框、一个按钮,等等。
接下来我们再看下 UIObjectProxy 的实现,其文档地址为:https://poco.readthedocs.io/en/latest/source/poco.proxy.html。
这里我们可以看到它实现了 __getitem__、__iter__、__len__ 等方法,另外观察到其还实现了 child、children、offspring 方法,这也就是 UIObjectProxy 可以实现链式调用和索引操作以及循环遍历的原因。
接下来我们再介绍几个比较常用的方法。
child
选择子节点,第一个参数是 name,即 UI 控件的名称,如 android.widget.LinearLayout 等等,另外还可以额外传入一些属性来进行辅助选择。
其返回结果同样是 UIObjectProxy 类型。
parent
选择父节点,无需参数,可以直接返回当前节点的父节点,同样是 UIObjectProxy 类型。
sibling
选择兄弟节点,第一个参数是 name,即 UI 控件的名称,另外还可以额外传入一些属性来进行辅助选择。
其返回结果同样是 UIObjectProxy 类型。
click、rclick、double_click、long_click
点击、右键点击、双击、长按操作,UIObjectProxy 对象直接调用即可。其接受参数 focus 指定点击偏移位置,sleep_interval 代表点击完成之后等待的秒数。
swipe
滑动操作,其接收参数 direction 代表滑动方向,focus 代表滑动焦点偏移量,duration 代表完成滑动所需时间。
wait
等待此节点出现,其接收参数 timeout 代表最长等待时间。
attr
获取节点的属性,其接收参数 name 代表属性名,如 visable、text、type、pos、size 等等。
get_text
获取节点的文本值,这个方法非常有用,利用它我们就可以获得某个文本节点内部的文本数据。
另外还有很多方法,这里暂时介绍这么多,更多的方法可以参考官方文档介绍: https://poco.readthedocs.io/en/latest/source/poco.proxy.html。
实战爬取
最后我们以一个 App 为例来完成数据的爬取。其下载地址为:https://app7.scrape.center/。
首先将 App 安装到手机上,进行简单的抓包发现其数据接口带有加密,同时 App 的逆向分析也有一定的难度,所以这里我们来采取 Airtest 来实现模拟爬取。
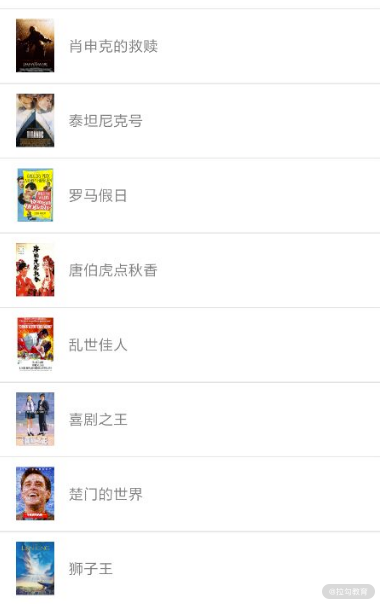
我们的目标就是要把所有的电影名称抓取下来,如图所示:
整体思路如下:
- 由于存在大量相似的节点,所以需要用循环的方式来遍历每个节点。
- 遍历节点之后获取到其真实的 TextView 节点,利用 get_text 方法提取文本值。
- 初始数据只有 10 条,数据的加载需要连续不断上拉,因此需要增加滑动操作。
- 提取的数据可能有重复,所以需要增加去重相关操作。
- 最后加载完毕之后,检测数据量不再发生变化,停止抓取。
由于整体思路比较简单,这里直接将代码实现如下:
from airtest.core.api import *
from poco.drivers.android.uiautomation import AndroidUiautomationPoco
PACKAGE_NAME = 'com.goldze.mvvmhabit'
poco = AndroidUiautomationPoco()
poco.device.wake()
stop_app(PACKAGE_NAME)
start_app(PACKAGE_NAME)
auto_setup(__file__)
screenWidth, screenHeight = poco.get_screen_size()
viewed = []
current_count, last_count = len(viewed), len(viewed)
while True:
last_count = len(viewed)
result = poco('android.support.v7.widget.RecyclerView').child('android.widget.LinearLayout')
result.wait(timeout=10)
for item in result:
text_view = item.child(type='android.widget.TextView')
if not text_view.exists():
continue
name = text_view.get_text()
if not name in viewed:
viewed.append(name)
print('名称', name)
current_count = len(viewed)
print('开始滑动')
swipe((screenWidth * 0.5, screenHeight * 0.7), vector=[0, -0.8], duration=3)
print('滑动结束')
sleep(5)
if current_count == last_count:
print('数量不再有变化,抓取结束')
break
整体思路如下:
- 首先在最开始的时候我们声明了 AndroidUiautomationPoco 对象,赋值为 poco,即获得了 App 的操作句柄。
- 接着调用了 stop_app 和 start_app 并传入包名实现了 App 的重启,确保是从头开始抓取的。
- 接着我们定义了一个无限循环,提取的是 android.support.v7.widget.RecyclerView 里面的 android.widget.LinearLayout 子节点,会一次性命中多个。
- 然后我们利用 for 循环遍历了每个节点,获取到了其中的 android.widget.TextView 节点,并用 get_text 提取了文本值,保存到 viewed 变量里面并去重。
- 遍历完成一遍之后,调用 swipe 方法滑动手机,进行上拉加载,同时滑动完毕之后等待一段时间。
- 重复以上步骤,直到 viewed 的数量不再变化,终止抓取。
运行如上代码便可以发现控制台输出了如下结果:
名称 霸王别姬
名称 这个杀手不太冷
名称 肖申克的救赎
名称 泰坦尼克号
名称 罗马假日
名称 唐伯虎点秋香
名称 乱世佳人
名称 喜剧之王
名称 楚门的世界
开始滑动
滑动结束
名称 狮子王
名称 V字仇杀队
开始滑动
滑动结束
名称 少年派的奇幻漂流
名称 美丽心灵
名称 初恋这件小事
名称 借东西的小人阿莉埃蒂
名称 一一
...
最后所有的电影名称就被我们提取出来了。
总结
以上我们便讲解了 AirtestIDE、Airtest、Poco 的基本用法,并用它们来完成了一个 App 数据的简单爬取。
无所不能的Xposed的使用
如果你对逆向有所涉猎的话,可能听说过 Hook,利用 Hook 技术我们可以在某一逻辑的前后加入自定义的逻辑处理代码,几乎可以实现任意逻辑的修改。
在前面的 JavaScript 逆向实战课时我们也初步体会了 Hook 的功效,如果你对 Hook 的概念还不太了解,可以搜索一下“Hook 技术”相关的内容来了解下。
对于 App 来说,Hook 技术应用非常广泛。比如朋友圈微信步数的修改,其实就是通过 Hook 数据发送的方式实现步数的修改。比如处理安卓的 SSL Pining,用 Hook 技术也可以修改 SSL 证书校验结果,实现校验的绕过。对于 App 爬虫来说,我们也可以使用 Hook 一些关键的方法获取方法执行前后的结果,从而实现数据的截获。
那这些技术怎么来实现呢?这里就不得不提一个框架,叫作 Xposed。
Xposed 介绍
Xposed 框架(Xposed Framework)是一套开源的,在 Android 高权限模式下运行的框架服务,可以在不修改 App 源码的情况下影响程序运行(修改系统)的框架服务,基于它可以制作出许多功能强大的模块,且在功能不冲突的情况下同时运作。
Xposed 框架的原理是通过替换系统级别的 /system/bin/app_process 程序控制 zygote 进程,使得app_process 在启动过程中会加载 XposedBridge.jar 这个 jar 包,这个 jar 包里面定义了对系统方法、属性的一系列 Hook 操作,同时还提供了几个 Hook API 供我们编写 Xposed 模块来使用。我们编写一个 Xposed 模块时,引用 Xposed 提供的几个 Hook 方法就可以实现对系统级别任意方法和属性的修改了。
这么说可能有点抽象,下面我们来编写一个 Xposed 模块带你体会一下 Xposed 的用法,最后再使用 Xposed 来实现一个真实 App 执行逻辑的修改。
本节要求
由于 Xposed 是运行在 Android 平台上的,所以本节我们的环境就和 Android 相关。
开始学习本节课之前,需要做如下准备工作:
-
配置好 Android 开发环境,开发环境的搭建流程可以参考下面的几个链接:
-
准备一个已经 ROOT 的安卓设备并连接好 PC,可以使用虚拟机或真机,比如我使用的是虚拟机网易 Mumu,已经自带了 ROOT 功能,当然如果你有已经 ROOT 的真机也是可以的。
-
安装好 jadx、jadx-gui,这是一款用来反编译 apk 的软件,安装参考链接见:https://github.com/skylot/jadx。
准备好了如上环境之后,我们就开始 Xposed 模块的编写吧。
Xposed Installer 安装
有了如上的环境后,首先我们需要先安装 Xposed。
要安装 Xposed 我们需要借助于一个叫作 Xposed Installer 的 App,它就是用来安装 Xposed 框架的,利用它我们可以下载和安装 Xposed 框架,同时还能查看和管理 Xposed 模块,还能查看一些 Xposed 框架输出的日志信息等。
怎么安装呢?
我们可以先打开 Xposed 的官网 https://repo.xposed.info/module/de.robv.android.xposed.installer,然后就可以看到一些有关 Xposed 的提示信息。
这里提示了这么一条重要信息:
For Android 5.0 or higher (Lollipop/Marshmallow), these versions don't work! Use this instead: http://forum.xda-developers.com/showthread.php?t=3034811
很明显,如果你的手机安卓版本在 5.0 以下,可以直接点击首页下方的 apk 下载,如果是 5.0 或更高版本,那么就到 http://forum.xda-developers.com/showthread.php?t=3034811 这个链接下载,后者的下载的真实链接是 https://forum.xda-developers.com/attachment.php?attachmentid=4393082&d=1516301692,可以直接点击下载。
注意:由于时间上的变化,下载地址以官方介绍为准。
下载完成之后会得到一个 apk 文件,我们可以直接在真机或模拟机上安装。
安装完成之后便会出现这样的一个图标:

这就代表 Xposed Installer 已经安装成功了。
下面我们打开它,它可能会提示需要 ROOT 权限,授予即可。
打开之后的界面可能如下所示:
这里它提示 Xposed 模块未安装,所以我们需要安装一下。
点击安装,如图所示。
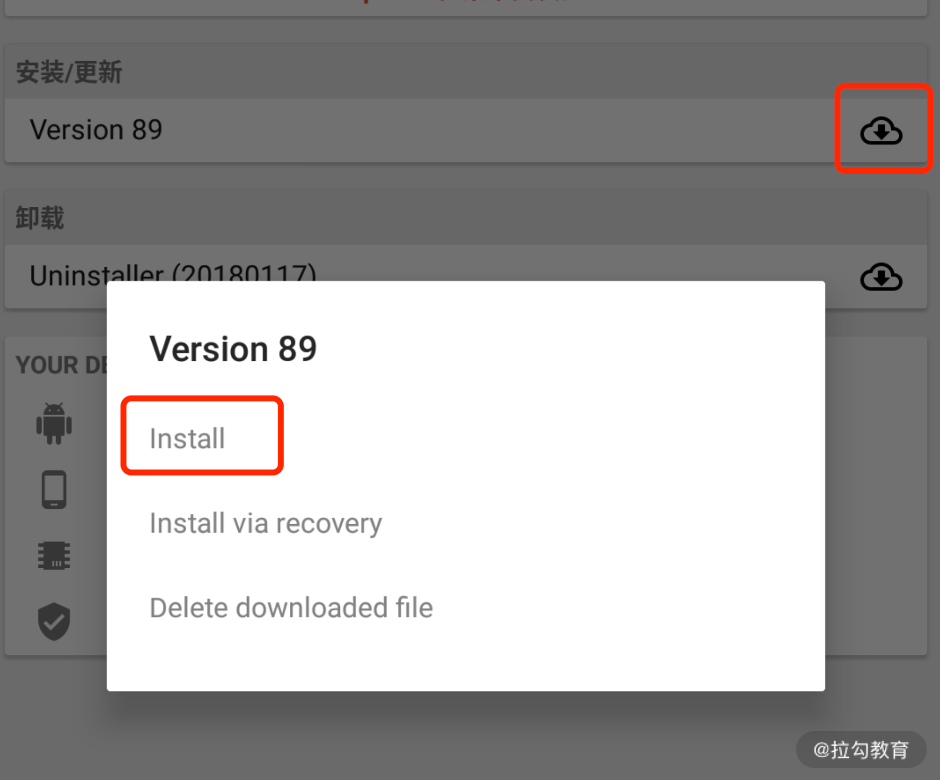
安装完成之后它会提示重启设备后生效,如图所示:
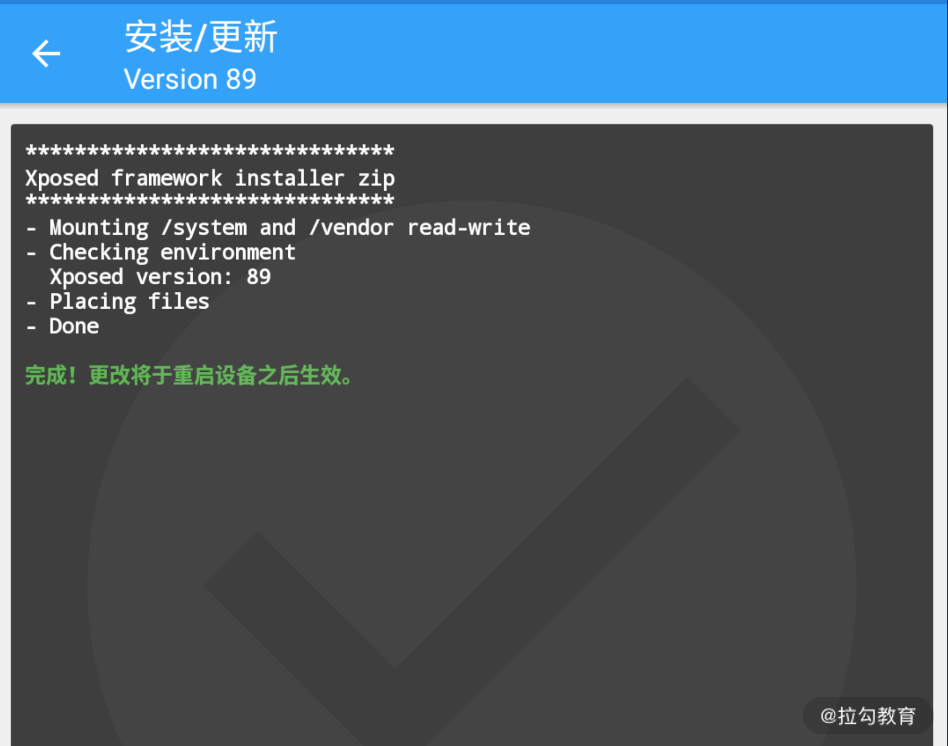
接着我们重启设备,便可以看到如下界面,代表 Xposed 框架已经安装并激活,如图所示:

这时候我们便可以开始编写 Xposed 模块了。
Xposed 模块
现在 Xposed 的生态非常庞大,基于 Xposed 开发的模块非常之多,点击下载菜单可以看到已有的发布的 Xposed 模块,如图所示:
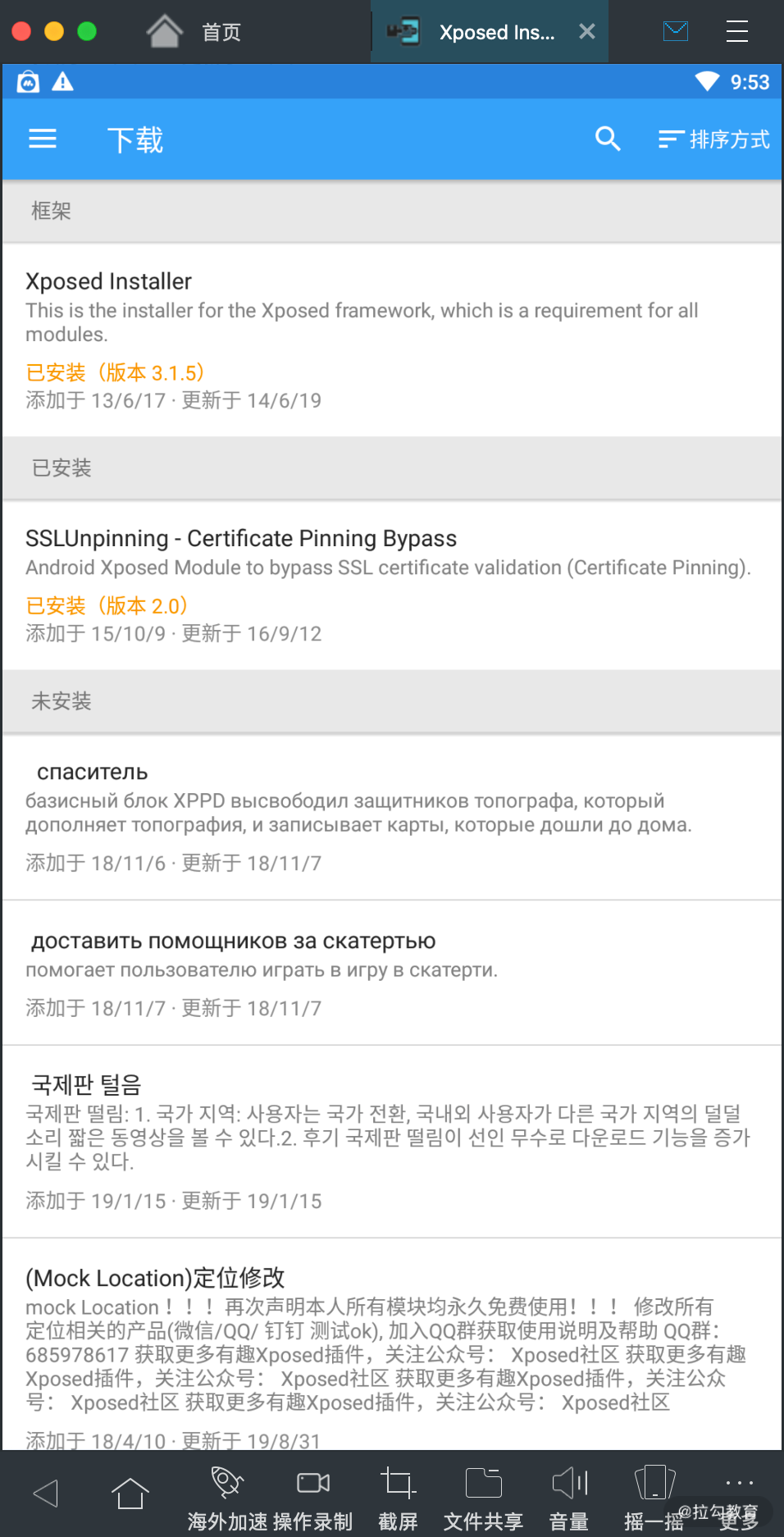
五花八门的模块非常多,比如修改微信步数、修改系统定位、自动抢红包等等。当然我们也可以编写自己的模块来实现想要的功能。
这时候你可能就会问了,这模块究竟是干吗的?它到底是一个什么东西?
其实本质上来说,它就是一个安卓 App,开发一个 Xposed 模块其实流程上就和开发一个安卓 App 差不多,只不过相比 App 开发来说多了下面四个步骤:
-
这个 App 里面要加上一些标识,标明这个 App 是一个 Xposed 模块,以便安装之后 Xposed 框架可以识别出来。
-
这个 App 里面需要引入 Xposed 的 jar 包,从而能实现 Hook 操作。
-
App 里面定义一些 Hook 操作,可以对本 App 或其他的 App 的逻辑进行修改。
-
定义完这些 Hook 操作逻辑之后,还需要告诉 Xposed 框架哪些是我们自己定义的 Hook 操作逻辑,以便 Xposed 执行这些 Hook 逻辑。
就这么四步,这四步这么来实现呢,下面我们来一步步实现。
Xposed 模块开发
下面我们来根据上面的四步来进行一个 Xposed 模块开发吧。
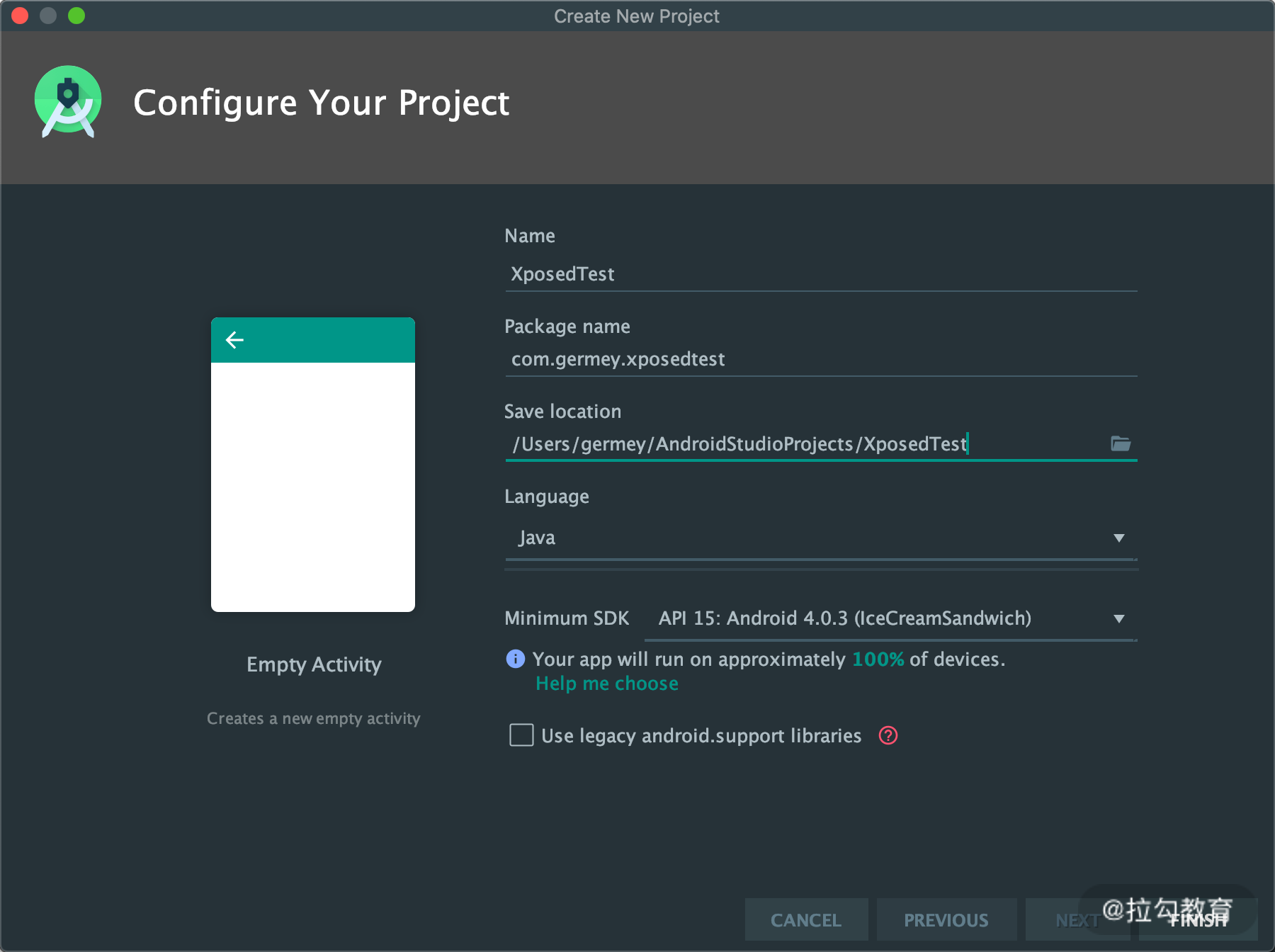
首先我们用 Android Studio 新建一个安卓项目,第一步提示我们选择 Activity,直接选择默认的 Empty Activity 即可,如图所示:
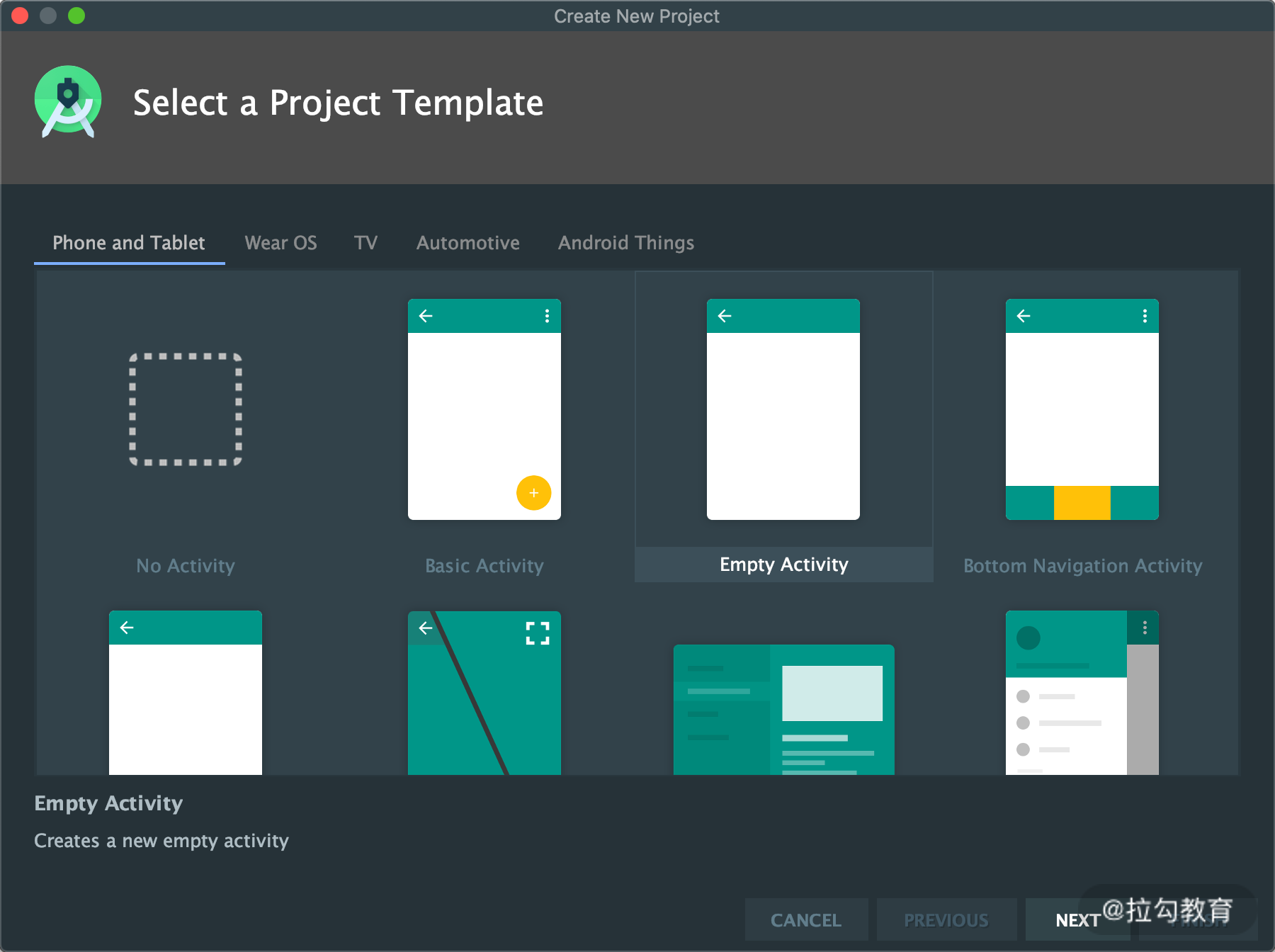
名称叫作 XposedTest,包名可以任意取,然后指定好项目路径和编写语言,同时指定最小 SDK 版本为 15,如图所示:
点击 FINISH,创建这个项目。
最后生成的界面如图所示:
然后我们开始第一步的配置,先配置一些标识符,标识这是一个 Xposed 模块。
我们打开 AndroidManifest.xml 文件,添加如下内容:
<meta-data
android:name="xposedmodule"
android:value="true" />
<meta-data
android:name="xposeddescription"
android:value="Xposed Test" />
<meta-data
android:name="xposedminversion"
android:value="53" />
到 application 标签内,和 activity 标签并列,最终内容如图所示:
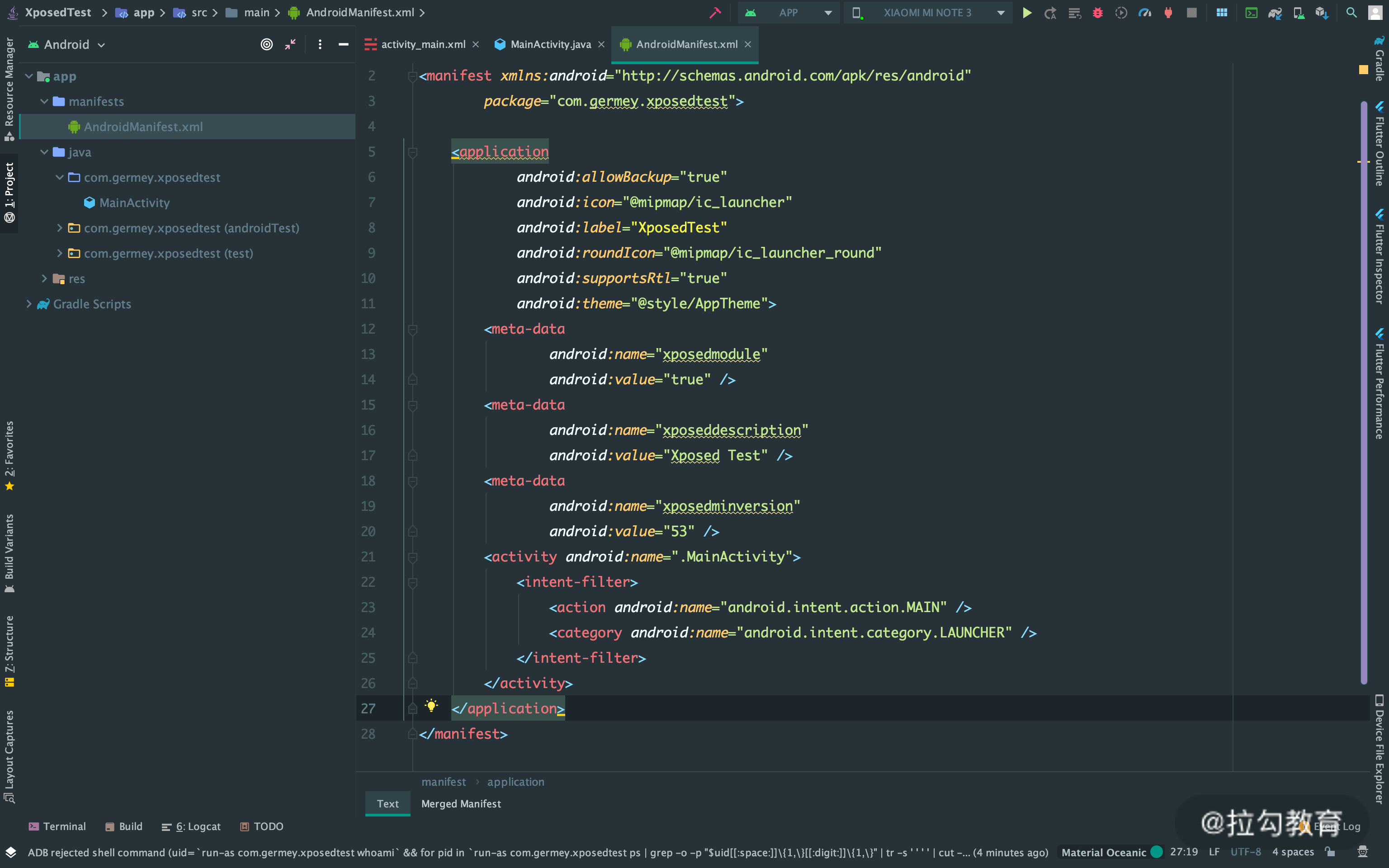
这里指定了三个 meta-data,分别如下。
-
xposedmodule:这里设置为 true,代表这是一个 Xposed 模块。
-
xposeddescription:模块的描述,填写模块描述就好,就是一个字符串。
-
xposedminversion:模块运行要求的 Xposed 最低版本号,这里是 53。
定义好这三个参数之后,把这个 App 安装到手机,Xposed 就能识别出这个 App 是一个 Xposed 模块了。
我们点击运行按钮,在手机上运行这个 App。这时候可以看到手机上出现了如下界面,如图所示:

这时候我们打开 Xposed Installer 的模块界面,就发现它检测到了这个模块,如图所示:
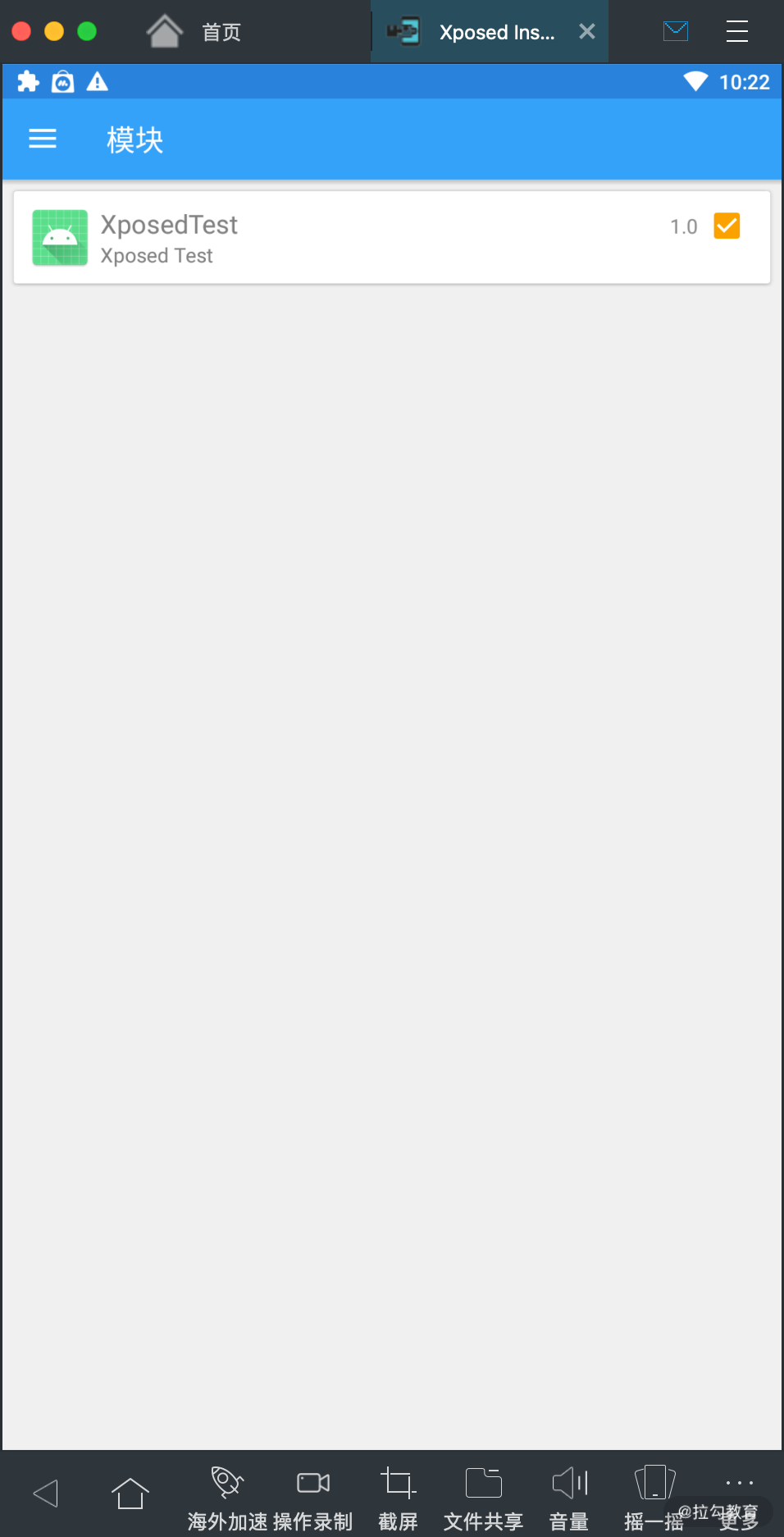
在这里我们把它勾选上,就成功启用了这个 Xposed 模块。不过值得注意的是,需要重启设备才能生效。可以手动启动设备或者通过 Xposed Installer 首页的重启选项来进行重启。
但是,现在启用了也没什么用啊,因为这个模块里面什么功能都还没有呢。
接下来我们再在项目中引入 Xposed 相关的 SDK,这样我们才能调用 Xposed 提供的一些 Hook 操作方法,实现 Hook 操作。
打开 app/build.gradle 文件,在 dependencies 区域添加如下两行代码:
compileOnly 'de.robv.android.xposed:api:82'
compileOnly 'de.robv.android.xposed:api:82:sources'
这是 Xposed 的 SDK,添加之后 Android Stuido 会检测到项目配置发生的变化,在右上角会提示一个“Sync Now”的选项,我们点击之后,新添加的 Xposed SDK 便会自动下载和安装,如图所示:
好,现在 Xposed 的 SDK 就安装成功了,下面我们就能使用里面的方法来实现逻辑的 Hook 了。
那怎么来实现逻辑的 Hook 呢?Hook 什么呢?那总得有点逻辑吧?哪来的逻辑呢?自己先写一个吧。
说干就干,这里我们就添加一个鼠标响应事件,点击之后触发一个算式计算的逻辑。
首先我们修改下页面内容,把当前的文本框设置成一个按钮,以便点击触发,修改 app/src/main/res/layout/activity_main.xml 文件,内容替换为如下内容:
<?xml version="1.0" encoding="utf-8"?>
<androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
tools:context=".MainActivity">
<Button
android:id="@+id/button"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:text="Test"
app:layout_constraintBottom_toBottomOf="parent"
app:layout_constraintEnd_toEndOf="parent"
app:layout_constraintStart_toStartOf="parent"
app:layout_constraintTop_toTopOf="parent" />
</androidx.constraintlayout.widget.ConstraintLayout>
这时候重新运行 App 就会出现一个按钮了,而不是一行文本框。接下来再修改下 MainActivity.java 文件,内容如下:
package com.germey.xposedtest;
import androidx.appcompat.app.AppCompatActivity;
import android.os.Bundle;
import android.view.View;
import android.widget.Button;
import android.widget.Toast;
import android.os.Bundle;
public class MainActivity extends AppCompatActivity {
private Button button;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
button = findViewById(R.id.button);
button.setOnClickListener(new View.OnClickListener() {
public void onClick(View v) {
Toast.makeText(MainActivity.this, showMessage(1, 2), Toast.LENGTH_SHORT).show();
}
});
}
public String showMessage(int x, int y) {
return "x + y = " + (x + y);
}
}
这里我们定义了一个 Button,然后使用 findViewById 方法从视图里面获取到了这个 Button 对象,同时我们为这个 Button 添加了一个点击事件,点击之后会生成一个 Toast 提示,其内容为 showMessage 方法返回的结果。
这个 showMessage 方法接收两个参数,是 int 类型的 x 和 y,返回的结果是一个字符串,即“x + y =”这个字符串再拼接上二者计算得到的结果,其实就是一个算数表达式。
这里 showMessage 在调用的时候我们传入了 1 + 2,所以最后 showMessage 显示的结果应该为“x + y = 3”,我们重新运行下 App,然后点击 TEST 按钮,可以看到如下运行结果:

这样我们的一个基本的逻辑就定义好了。
定义好了之后呢,下一步我们就来用 Xposed 进行 Hook 吧,我们在 MainActivity.java 同级新建一个 Java Class,内容如下:
package com.germey.xposedtest;
import de.robv.android.xposed.IXposedHookLoadPackage;
import de.robv.android.xposed.XC_MethodHook;
import de.robv.android.xposed.XposedBridge;
import de.robv.android.xposed.XposedHelpers;
import de.robv.android.xposed.callbacks.XC_LoadPackage;
public class HookMessage implements IXposedHookLoadPackage {
public void handleLoadPackage(XC_LoadPackage.LoadPackageParam loadPackageParam) throws Throwable {
if (loadPackageParam.packageName.equals("com.germey.xposedtest")) {
XposedBridge.log("Hooked com.germey.xposedtest Package");
Class clazz = loadPackageParam.classLoader.loadClass(
"com.germey.xposedtest.MainActivity");
XposedHelpers.findAndHookMethod(clazz, "showMessage", int.class, int.class, new XC_MethodHook() {
protected void beforeHookedMethod(MethodHookParam param) throws Throwable {
XposedBridge.log("Called beforeHookedMethod");
param.args[0] = 2;
XposedBridge.log("Changed args 0 to " + param.args[0]);
}
protected void afterHookedMethod(MethodHookParam param) throws Throwable {
XposedBridge.log("Called afterHookedMethod");
}
});
}
}
}
这里我们就定义了 Hook 的相关逻辑了,这里梳理几个关键的点:
-
这里的 class 实现了 IXposedHookLoadPackage 接口,需要定义 handleLoadPackage 这个方法,这个方法会在每个 App 包加载时执行。
-
在 handleLoadPackage 里面我们通过
loadPackageParam.packageName获取到了 App 包名,然后判断是否是我们当前 App 的包名。这里包名可以是任意 App 的包名,不一定是当前 App 的包名,只不过是因为我们为了方便,在当前 App 里面定义了一个逻辑,所以这里我们 Hook 的是当前 App 的逻辑,才填写了当前 App 的包名。 -
利用 loadClass 方法并指定 class 的路径可以动态地加载这个 class,是一个 Class 对象。
-
利用 XposedHelpers 提供的 findAndHookMethod 方法可以从 class 里面查找对应的方法,这里需要传入的参数分别为 Class 对象,方法名称,方法的参数类型,处理方法。这里方法的参数类型是有几个写几个,比如这里 showMessage 有两个 int 类型的参数,这里就需要顺次写两个 int.class,如果是其他的类型也是分别写类型再加 class 的声明。
-
XC_MethodHook 里面定义了我们施行 Hook 的真正逻辑,这里通常可以实现两个方法,分别叫作 beforeHookedMethod 和 afterHookedMethod,分别代表在被 Hook 方法(这里为 showMessage)执行前的操作和执行后的操作,同时二者都有一个 MethodHookParam 类型的参数,里面包含了方法执行的参数和结果等信息。
-
一般来说 beforeHookedMethod 方法可以用来修改被 Hook 方法的参数内容,或者直接定义被 Hook 方法的运行流程。afterHookedMethod 可以用来对被 Hook 方法进行后处理,比如对被 Hook 方法的结果进行拦截、保存、转发、修改等操作。
-
XposedBridge 里的 log 方法可以记录将 Log 信息记录到 Xposed Installer 里面,我们通过 Xposed Installer 里面日志页面就可以看到对应结果,方便做调试使用。
这里我们先对 beforeHookedMethod 处理,对 param 的 args 属性做了处理,这里的 args 属性是一个列表,就是 showMessage 方法的调用参数,因为我们之前传入的是 1 和 2,所以这里 args 属性的值其实就是 [1, 2],那这里我们是把它改写了一下,把第一个内容改写成了 2,那这里 args 其实就会变成 [2, 2] 了。
好,现在 Hook 的逻辑我们已经实现好了,还差最后一步,那就是告诉 Xposed 我们的 Hook 逻辑是定义在哪里了,我们需要新建一个 Xposed 入口文件。
在 main 文件夹新建一个 assets folder,如图所示:

然后在 assets 文件夹下新建一个 xposed_init 文件,不需要有任何后缀,如图所示:
其内容就把 Hook 的这个类的路径写好就好了,内容如下:
com.germey.xposedtest.HookMessage
好,这样保存之后,Xposed 就能自动读取这个 xposed_init 文件来执行我们自定义的 Hook 逻辑了。
最后,我们就来重新运行看下效果吧。记得安装完成之后重启一下 Xposed,否则是没有效果的。
重启模块之后,点击 TEST 按钮,可以看到就出现了如下效果,如图所示:

这里可以看到,最后的运行效果就不一样了,出现了“x + y = 4”的这个现象,这说明通过 beforeHookedMethod 的定义,我们成功把 args 的第一个参数,也就是 x 修改成了 2,而第二个参数没有修改,还是 2,最后就相当于 showMessage 调用之前,两个参数就被修改成了 2 和 2,最后答案就是 4 了。这下我们就体会到了 beforeHookedMethod 的用法了。
刚才我们是用了 beforeHookedMethod 来实现了参数替换的效果,接下来我们再来体会一下 afterHookedMethod 的用法,它可以对方法的返回结果进行后处理,比如这里我们把 afterHookedMethod 修改为如下内容:
protected void afterHookedMethod(MethodHookParam param) throws Throwable {
XposedBridge.log("Called afterHookedMethod");
param.setResult("Hooked");
}
这里我们增加了 param 的 setResult 方法的调用,利用它我们可以直接将方法的返回值修改掉。
重新运行这个模块,然后重启手机,同样地还是点击 TEST 按钮,这时候我们发现其结果就变成了如下内容,如图所示:
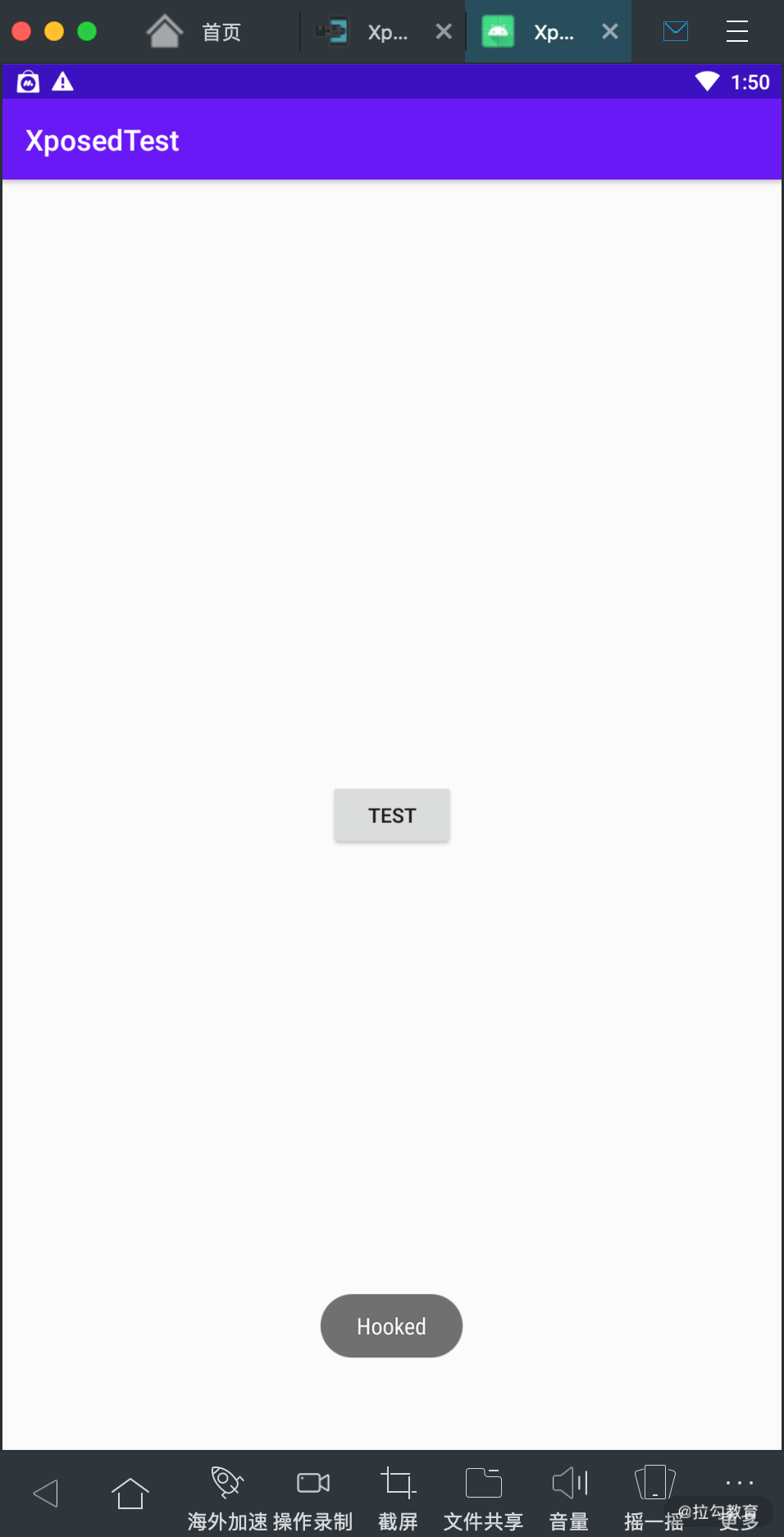
可以看到最后方法的返回结果被修改了,这正是 afterHookedMethod 所起的作用。
由此,我们通过 beforeHookedMethod 和 afterHookedMethod 的修改可以实现 showMessage 在调用前和调用后的修改。
好,最后我们再来看下日志,打开 Xposed Installer 的日志页面,可以看到内容如图所示:
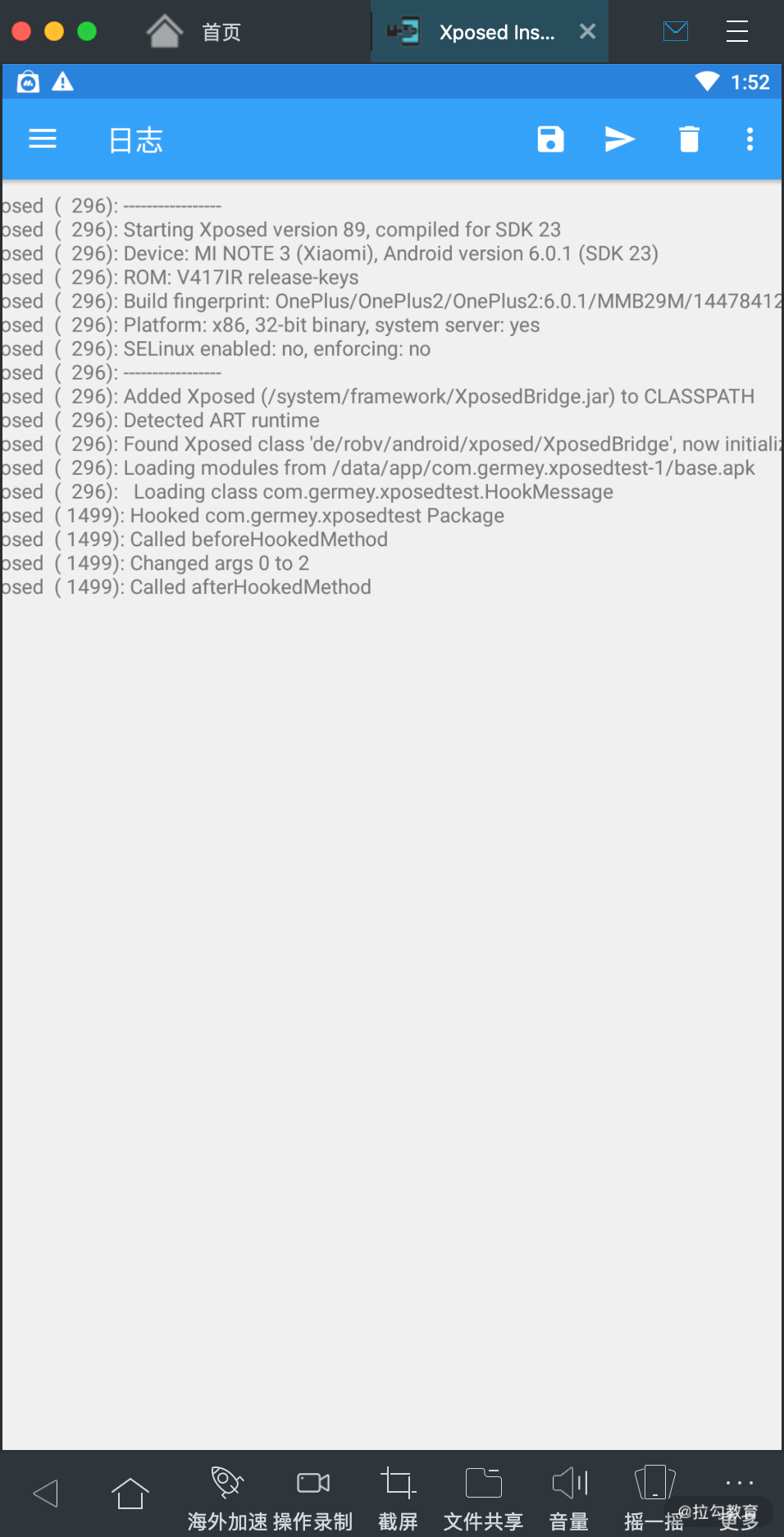
可以看到这里就输出了我们用 XposedBridge 的 log 方法输出的内容。
OK,到此为止我们就实现了 Xposed 的 Hook 逻辑了,通过这个案例你应该就能体会到 Xposed 的效用了。
真实 App 的修改
好,下面我们再来使用一个真实的 App 为样例来进行一下 Hook 操作吧,我们来实现通过 Hook App 的某个方法来达到修改 App 的运行效果的作用。
这个 App 的下载地址为:https://app1.scrape.center/。
下载完成之后,我们安装一下,可以看到不断下拉的过程中会有电影数据加载出来,如图所示。
通过观察我们可以发现每刷新一次,就会加载出 10 条数据,一共 100 条。
那这个加载数量我们可以通过 Xposed 修改吗?比如修改成一次加载 5 条能做到吗?当然是可以的。
但要修改的话,我们得需要知道 App 的一些逻辑,或者它的一些包路径,方法名之类的内容。
那这个怎么来处理呢?这时候我们可能就需要对 App 的安装包进行反编译了。
由于这个 App 比较简单,没有设置加固,所以这里我们直接使用 jadx 或 jadx-gui 就可以把源码反编译出来了。
这里我使用的是 jadx-gui,我们打开 jadx-gui,然后直接打开 apk 文件,就可以看到反编译后的结果了,如图所示:
通过 App 的一些抓包操作可以找到 API 请求的 URL Path 为 /api/movie,我们使用 jadx-gui 搜索下这个入口,就能找到其原始的一些定义,如图所示:
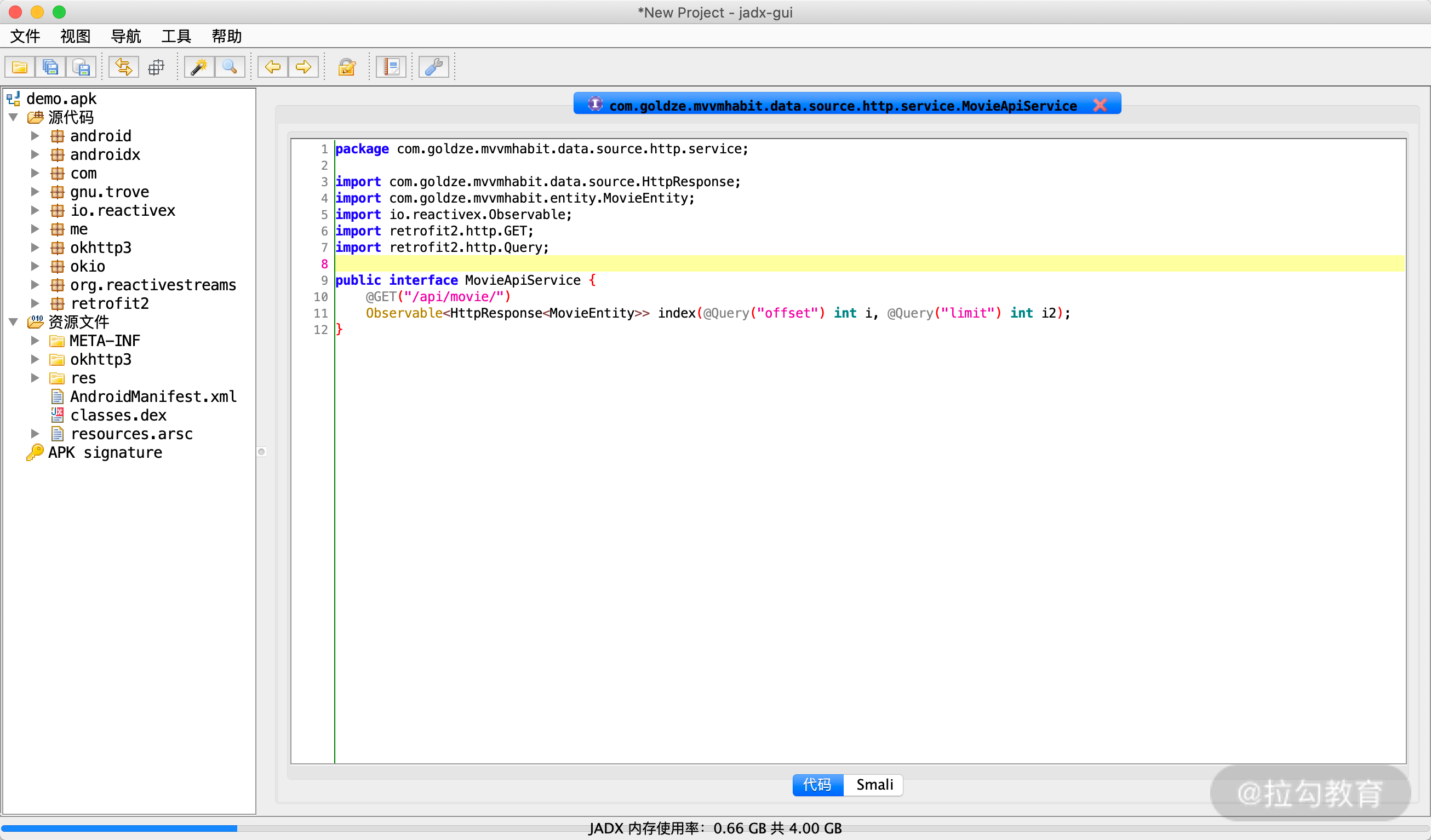
好,这时候呢我们可以大体定位到一些数据的操作就在 com.goldze.mvvmhabit.data 这个路径下,我们打开看看这里,同时借助于一些方法的交叉引用分析,可以大致分析到此处 index 方法的调用是在 com.goldze.mvvmhabit.data.MainRepository 里的 index 方法里。
实现如下:
public Observable<HttpResponse<MovieEntity>> index(int page, int limit) {
return this.mHttpDataSource.index(page, limit);
}
这里其实就很清楚了,它接受两个参数,一个是 page,一个 limit,最后调用了 mHttpDataSource 的 index 方法获得了 Response 的结果,并封装成一个 Observable 对象。
好,那我们就来 Hook 一下这个方法吧。我们还是在刚才的 XposedTest 这个项目下,另外新建一个 class,名字叫作 HookAPI,同时还是按照之前的方法来修改一下包名、类名、方法名等等,内容修改如下:
package com.germey.xposedtest;
import de.robv.android.xposed.IXposedHookLoadPackage;
import de.robv.android.xposed.XC_MethodHook;
import de.robv.android.xposed.XposedBridge;
import de.robv.android.xposed.XposedHelpers;
import de.robv.android.xposed.callbacks.XC_LoadPackage;
public class HookAPI implements IXposedHookLoadPackage {
public void handleLoadPackage(XC_LoadPackage.LoadPackageParam loadPackageParam) throws Throwable {
if (loadPackageParam.packageName.equals("com.goldze.mvvmhabit")) {
XposedBridge.log("Hooked com.goldze.mvvmhabit Package");
Class clazz = loadPackageParam.classLoader.loadClass(
"com.goldze.mvvmhabit.MainRepository");
XposedHelpers.findAndHookMethod(clazz, "index", int.class, int.class, new XC_MethodHook() {
protected void beforeHookedMethod(MethodHookParam param) throws Throwable {
XposedBridge.log("Called beforeHookedMethod");
param.args[1] = 5;
XposedBridge.log("Changed args 0 to " + param.args[0]);
}
protected void afterHookedMethod(MethodHookParam param) throws Throwable {
XposedBridge.log("Called afterHookedMethod");
}
});
}
}
}
这里我们就利用 beforeHookedMethod 方法把 args 的第二个参数修改成了 5,这样 limit 每次调用就不再是 10 了,而是 5,照理来说每次加载就会返回 5 条数据了。
另外我们还需要在 xposed_init 里面定义好这个入口文件,内容修改如下:
com.germey.xposedtest.HookMessage
com.germey.xposedtest.HookAPI
好,接下来重新安装这个 Xposed 模块,然后重启手机,接着再运行这个 Xposed 模块。
下面我们再重新打开刚才被 Hook 的 App,看到如下的加载效果,如图所示:
可以看到这里加载的数据就变成了 5 条,而不再是原来的 10 条,每次上拉刷新也都是 5 条数据了。
到此,我们就通过 Xposed 通过 Hook 的方式修改了 App 的运行效果,而没有去修改原始 App 的任何一行代码。
Xposed API
最后再来看下 Xposed 提供的 API。
其实刚才所说的 Hook 操作只是 Xposed 的其中一个 API,即 findAndHookMethod 的用法。我们可以查看 Xposed 的所有的 API,链接为 https://api.xposed.info/reference/de/robv/android/xposed/XposedHelpers.html。
在这里我们可以看到有如下的一些 API,这里简单列举一下。
-
callStaticMethod:调用静态方法。
-
findAndHookConstructor:查找并 Hook 构造方法。
-
findClassIfExists:查找某个类是否存在。
-
findField:获取成员变量。
有很多 API 是有类似或重合的功能的,这里就不再一一列举了,感兴趣的话你可以看官方的文档说明。
另外也非常推荐你研究一下 Xposed 里面的各个 package 的用法,API 见 https://api.xposed.info/reference/de/robv/android/xposed/package-summary.html。
另外也欢迎你多去研究一些优秀的 Xposed 模块,比如 https://devsjournal.com/best-xposed-modules.html 里面列举了几款很受欢迎的 Xposed 模块,另外还有 Xposed 中文站 http://xposed.appkg.com/,你可以找一些优秀的模块的源码来研究一下,收获会非常大的。
总结
本文我们介绍了 Xposed 的基本理念,并通过案例来实现了 Xposed Hook App 的流程。
Xposed 的功能非常强大,利用它,App 尽在我们掌控之中,为所欲为不再是奢望。
本节代码:https://github.com/Python3WebSpider/XposedTest。
参考链接
# App逆向的常见技巧现在我们可以看到很多 App 在请求 API 的时候都有加密参数,前面我们也介绍了一种利用 mitmdump 来实时抓取数据的方法,但是这总归还有些不方便的地方。
如果要想拿到 App 发送的请求中包含哪些加密参数,就得剖析本源,深入到 App 内部去找到这些加密参数的构造逻辑,理清这些逻辑之后,我们就能自己用算法实现出来了。这其中就需要一定的逆向操作,我们可能需要对 App 进行反编译,然后通过分析源码的逻辑找到对应的加密位置。
所以,本课时我们来用一个示例介绍App 逆向相关操作。
案例介绍
这里我们首先以一个 App 为例介绍这个 App 的抓包结果和加密情况,然后我们对这个 App 进行逆向分析,最后模拟实现其中的加密逻辑。
App 的下载地址为:https://app5.scrape.center/
我们先运行一下这个 App,上拉滑动,一些电影数据就会呈现出来了,界面如下:
这时候我们用 Charles 抓包来试一下,可以看到类似 API 的请求 URL 类似如下:https://app5.scrape.center/api/movie/?offset=0&limit=10&token=NDVjMTdjNjk5YWM2NWZkOGU5ZjFjNWEyN2MzNjhiYjIwMzRlZDU3ZiwxNTkxMjgyMzcz%0A,这里我们可以发现有三个参数,分别为 offset、limit 还有 token,其中 token 是一个非常长的加密字符串,我们也不好直观地推测其生成逻辑。
本课时我们就来介绍一下逆向相关的操作,通过逆向操作获得 apk 反编译后的代码,然后追踪这个 token 的生成逻辑是怎样的,最后我们再用代码把这个逻辑实现出来。
App 逆向其实多数情况下就是反编译得到 App 的源码,然后从源码里面找寻特定的逻辑,本课时就来演示一下 App 的反编译和入口点查找操作。
环境准备
在这里我们使用的逆向工具叫作 JEB。
JEB 是一款专业的安卓应用程序的反编译工具,适用于逆向和审计工程,功能非常强大,可以帮助逆向人员节省很多逆向分析时间。利用这个工具我们能方便地获取到 apk 的源码信息,逆向一个 apk 不在话下。
JEB 支持 Windows、Linux、Mac 三大平台,其官网地址为 https://www.pnfsoftware.com/,你可以在官网了解下其基本介绍,然后通过搜索找到一些完整版安装包下载。下载之后我们会看到一个 zip 压缩包,解压压缩包之后会得到如下的内容:
在这里我们直接运行不同平台下的脚本文件即可启动 JEB。比如我使用的是 Mac,那我就可以在此目录下执行如下命令:
sh jeb_macos.sh
这样我们就可以打开 JEB 了。打开 JEB 之后,我们把下载的 apk 文件直接拖拽到 JEB 里面,经过一段时间处理后,会发现 JEB 就已经将代码反编译完成了,如图所示:
这时候我们可以看到在左侧 Bytecode 部分就是反编译后的代码,在右侧显示的则是 Smali 代码,通过 Smali 代码我们大体能够看出一些执行逻辑和数据操作等过程。
现在我们得到了这些反编译的内容,该从哪个地方入手去找入口呢?
由于这里我们需要找的是请求加密参数的位置,那么最简单的当然是通过 API 的一些标志字符串来查找入口了。API 的 URL 里面包含了关键字 /api/movie,那么我们自然就可以通过这个来查找了。
我们可以在 JEB 里面打开查找窗口,查找 /api/movie,如图所示:
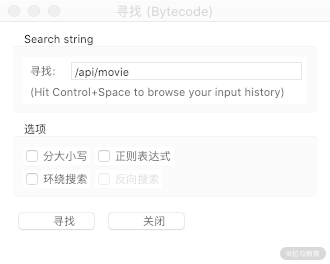
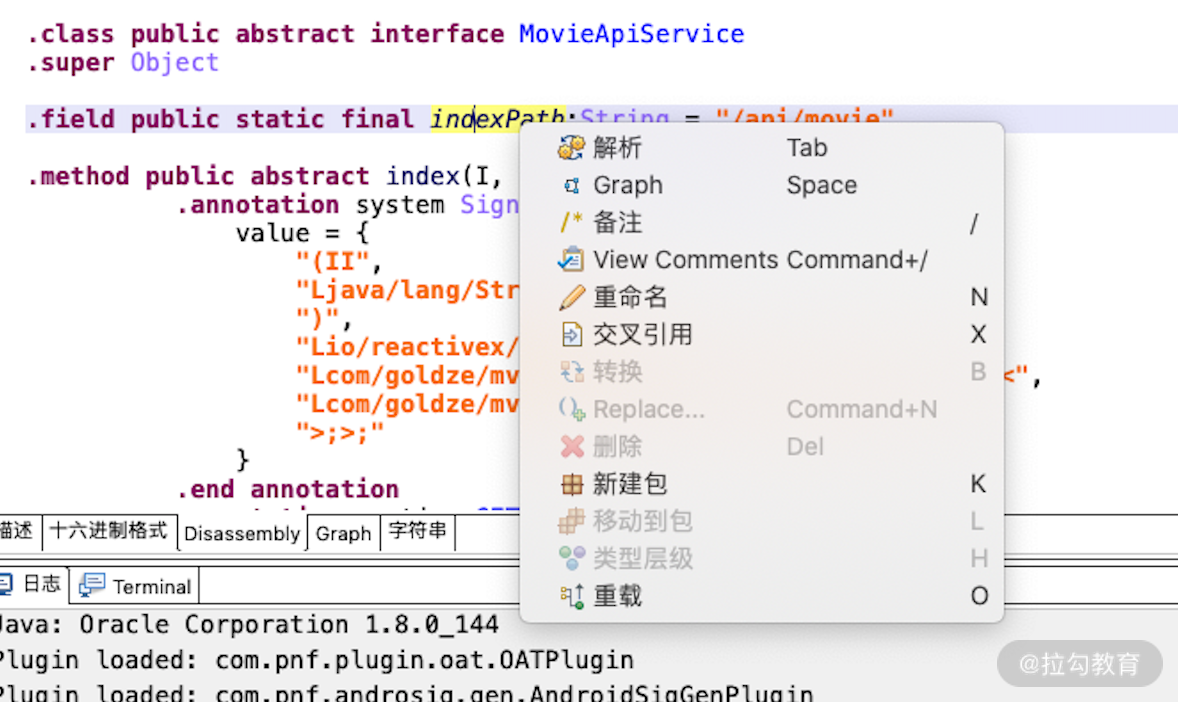
这时候我们发现就找到了一个对应的声明如下:
.field public static final indexPath:String = "/api/movie"
这里其实就是声明了一个静态不可变的字符串,叫作 indexPath。但这里是 Smali 代码呀?我们怎么去找到它的源码位置呢?
这时候我们可以右键该字符串,选择解析选项,这时 JEB 就可以成功帮我们定位到 Java 代码的声明处了。
这时候我们便可以看到其跳转到了如下页面:
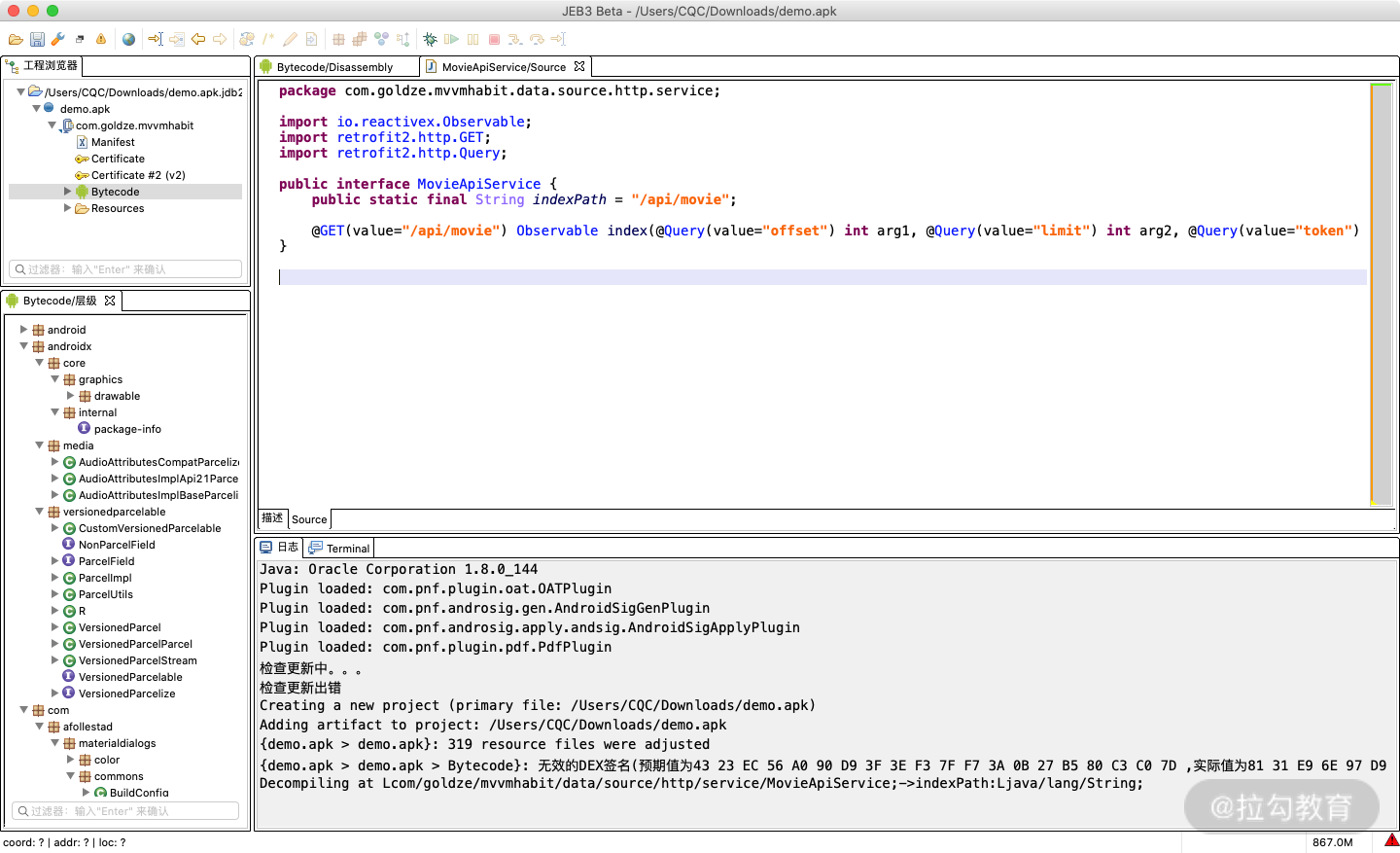
这里我们就能看到 indexPath 的原始声明,同时还看到了一个 index 方法的声明,包含三个参数 offset、limit 还有 token,由此可以发现,这参数和声明其实恰好和 API 的请求 URL 格式是相同的。
但这里还观察到这个是一个接口声明,一定有某个类实现了这个接口。
我们这时候可以顺着 index 方法来查询是什么类实现了这个 index 方法,在 index 方法上面右键选择“交叉引用”,如图所示:
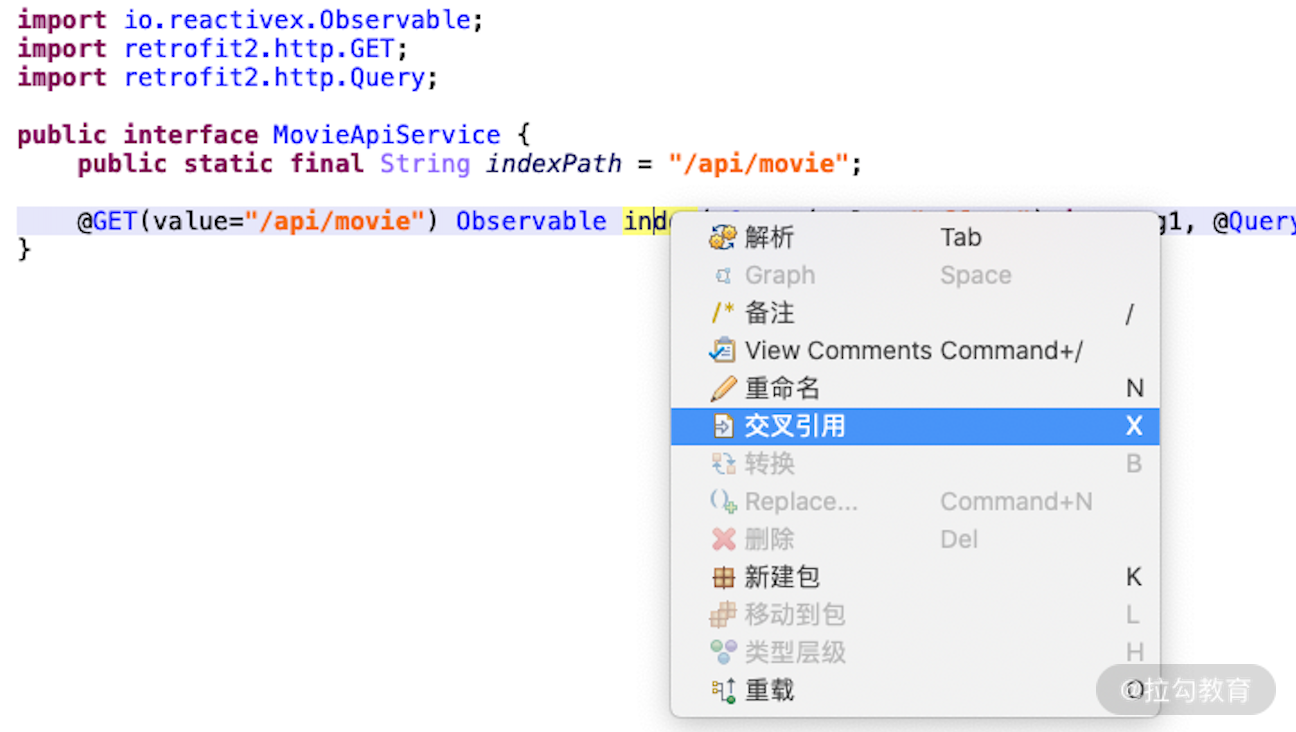
这时候我们可以发现这里弹出了一个窗口,找到了对应的位置,如图所示:
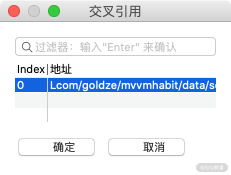
我们选中它,点击确定,这时候就跳转到了对应的 index 实现的位置了,如图所示:
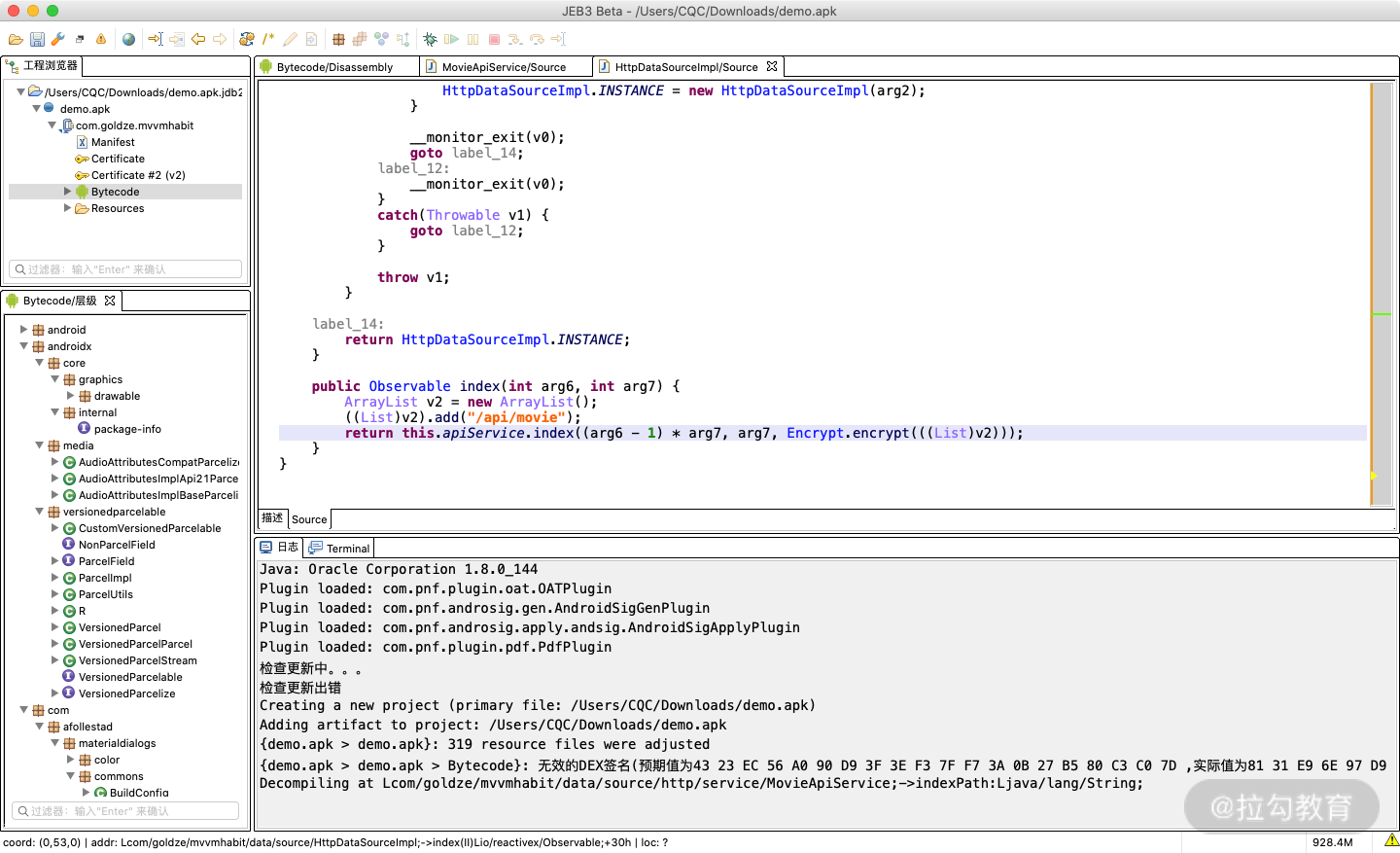
这里 index 方法的实现如下:
public Observable index(int arg6, int arg7) {
ArrayList v2 = new ArrayList();
((List)v2).add("/api/movie");
return this.apiService.index((arg6 - 1) * arg7, arg7, Encrypt.encrypt(((List)v2)));
}
就能很轻易地发现一个类似 encrypt 的方法,代表加密的意思,其参数就是 v2,而 v2 就是一个 ArrayList,包含一个元素,就是 /api/movie 这个字符串。
这时候我们再通过交叉引用找到 Encrypt 的定义,跳转到如图所示的位置:
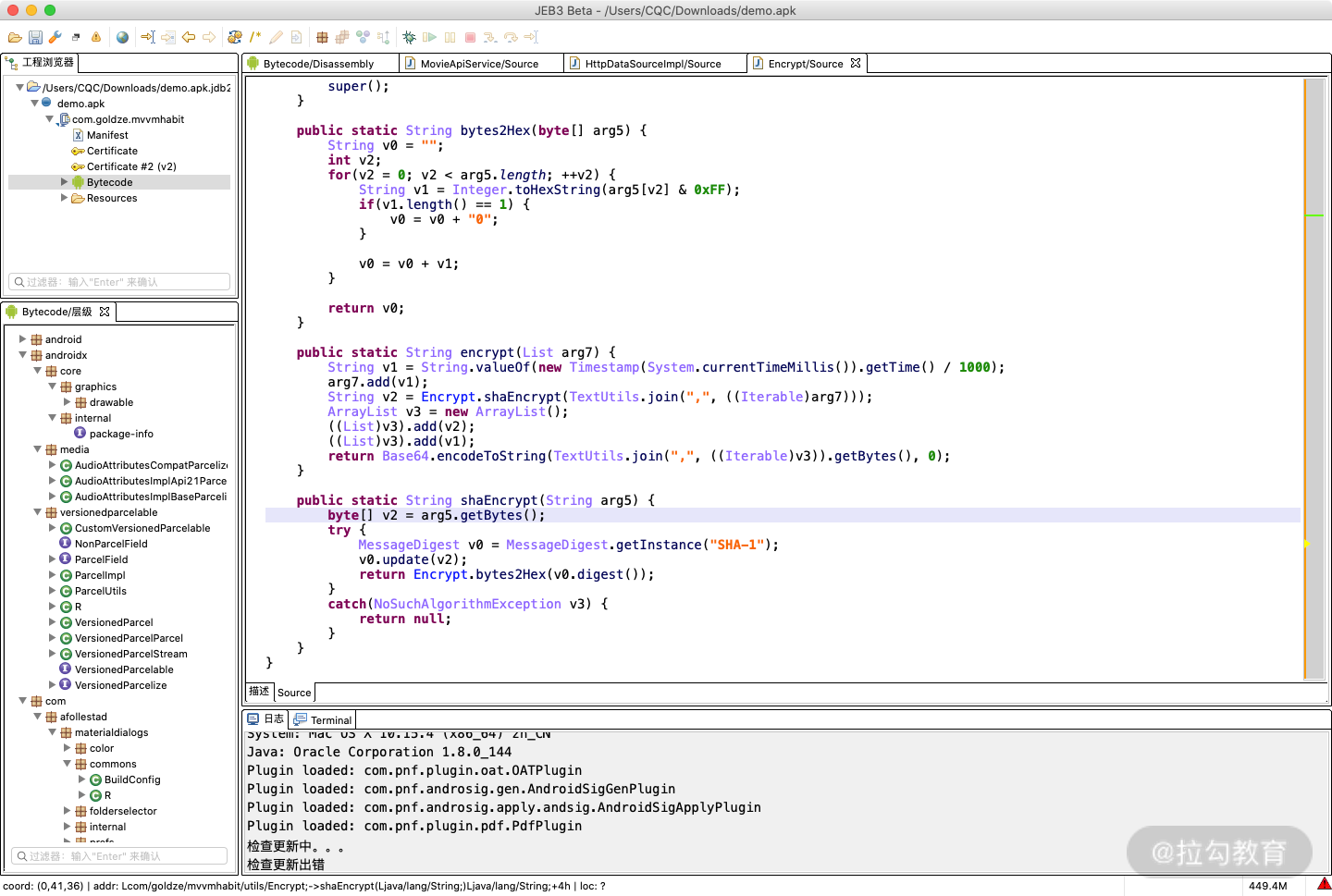
这里可以发现 encrypt 的方法实现如下:
public static String encrypt(List arg7) {
String v1 = String.valueOf(new Timestamp(System.currentTimeMillis()).getTime() / 1000);
arg7.add(v1);
String v2 = Encrypt.shaEncrypt(TextUtils.join(",", ((Iterable)arg7)));
ArrayList v3 = new ArrayList();
((List)v3).add(v2);
((List)v3).add(v1);
return Base64.encodeToString(TextUtils.join(",", ((Iterable)v3)).getBytes(), 0);
}
这里我们分析一下,传入的参数就是 arg7,刚才经过分析可知 arg7 其实就是一个长度为 1 的列表,其内容就是一个字符串,即 ["/api/movie"]。
紧接着看逻辑,这里又定义了一个 v1 的字符串,其实就是获取了时间戳信息,然后把结果加入 arg7,现在 arg7 就有两个内容了,一个是 /api/movie,另一个是时间戳。
接着又声明了 v2,这里经过分析可知是将 arg7 使用逗号拼接起来,然后调用了 shaEncrypt 操作,而 shaEncrypt 经过观察其实就是 SHA1 算法。
紧接着又声明了一个 ArrayList,把 v2 和 v1 的结果加进去。最后把 v3 的内容使用逗号拼接起来,然后 Base64 编码即可。
好,现在整体的 token 加密的逻辑就理清楚了。
模拟
了解了基本的算法流程之后,我们可以用 Python 把这个流程实现出来,代码实现如下:
import hashlib
import time
import base64
from typing import List, Any
import requests
INDEX_URL = 'https://app5.scrape.center/api/movie?limit={limit}&offset={offset}&token={token}'
LIMIT = 10
OFFSET = 0
def get_token(args: List[Any]):
timestamp = str(int(time.time()))
args.append(timestamp)
sign = hashlib.sha1(','.join(args).encode('utf-8')).hexdigest()
return base64.b64encode(','.join([sign, timestamp]).encode('utf-8')).decode('utf-8')
args = ['/api/movie']
token = get_token(args=args)
index_url = INDEX_URL.format(limit=LIMIT, offset=OFFSET, token=token)
response = requests.get(index_url)
print('response', response.json())
这里最关键的就是 token 的生成过程,我们定义了一个 get_token 方法来实现,整体上思路就是上面梳理的内容:
-
列表中加入当前时间戳;
-
将列表内容用逗号拼接;
-
将拼接的结果进行 SHA1 编码;
-
将编码的结果和时间戳再次拼接;
-
将拼接后的结果进行 Base64 编码。
最后运行结果如下:
response {'count': 100, 'results': [{'id': 1, 'name': '霸王别姬', 'alias': 'Farewell My Concubine', 'cover': 'https://p0.meituan.net/movie/ce4da3e03e655b5b88ed31b5cd7896cf62472.jpg@464w_644h_1e_1c', 'categories': ['剧情', '爱情'], 'published_at': '1993-07-26', 'minute': 171, 'score': 9.5, 'regions': ['中国大陆', '中国香港']}, {'id': 2, 'name': '这个杀手不太冷', 'alias': 'Léon', 'cover': 'https://p1.meituan.net/movie/6bea9af4524dfbd0b668eaa7e187c3df767253.jpg@464w_644h_1e_1c', 'categories': ['剧情', '动作', '犯罪'], 'published_at': '1994-09-14', 'minute': 110, 'score': 9.5, 'regions': ['法国']}, {'id': 3, 'name': '肖申克的救赎', 'alias': 'The Shawshank Redemption', 'cover': 'https://p0.meituan.net/movie/283292171619cdfd5b240c8fd093f1eb255670.jpg@464w_644h_1e_1c', 'categories': ['剧情', '犯罪'], 'published_at': '1994-09-10', 'minute': 142, 'score': 9.5, 'regions': ['美国']}, {'id': 4, 'name': '泰坦尼克号', 'alias': 'Titanic', 'cover': 'https://p1.meituan.net/movie/b607fba7513e7f15eab170aac1e1400d878112.jpg@464w_644h_1e_1c', 'categories': ['剧情', '爱情', '灾难'], 'published_at': '1998-04-03', 'minute': 194, 'score': 9.5, 'regions': ['美国']}, {'id': 5, 'name': '罗马假日', 'alias': 'Roman Holiday', 'cover': 'https://p0.meituan.net/movie/289f98ceaa8a0ae737d3dc01cd05ab052213631.jpg@464w_644h_1e_1c', 'categories': ['剧情', '喜剧', '爱情'], 'published_at': '1953-08-20', 'minute': 118, 'score': 9.5, 'regions': ['美国']}, {'id': 6, 'name': '唐伯虎点秋香', 'alias': 'Flirting Scholar', 'cover': 'https://p0.meituan.net/movie/da64660f82b98cdc1b8a3804e69609e041108.jpg@464w_644h_1e_1c', 'categories': ['喜剧', '爱情', '古装'], 'published_at': '1993-07-01', 'minute': 102, 'score': 9.5, 'regions': ['中国香港']}, {'id': 7, 'name': '乱世佳人', 'alias': 'Gone with the Wind', 'cover': 'https://p0.meituan.net/movie/223c3e186db3ab4ea3bb14508c709400427933.jpg@464w_644h_1e_1c', 'categories': ['剧情', '爱情', '历史', '战争'], 'published_at': '1939-12-15', 'minute': 238, 'score': 9.5, 'regions': ['美国']}, {'id': 8, 'name': '喜剧之王', 'alias': 'The King of Comedy', 'cover': 'https://p0.meituan.net/movie/1f0d671f6a37f9d7b015e4682b8b113e174332.jpg@464w_644h_1e_1c', 'categories': ['剧情', '喜剧', '爱情'], 'published_at': '1999-02-13', 'minute': 85, 'score': 9.5, 'regions': ['中国香港']}, {'id': 9, 'name': '楚门的世界', 'alias': 'The Truman Show', 'cover': 'https://p0.meituan.net/movie/8959888ee0c399b0fe53a714bc8a5a17460048.jpg@464w_644h_1e_1c', 'categories': ['剧情', '科幻'], 'published_at': None, 'minute': 103, 'score': 9.0, 'regions': ['美国']}, {'id': 10, 'name': '狮子王', 'alias': 'The Lion King', 'cover': 'https://p0.meituan.net/movie/27b76fe6cf3903f3d74963f70786001e1438406.jpg@464w_644h_1e_1c', 'categories': ['动画', '歌舞', '冒险'], 'published_at': '1995-07-15', 'minute': 89, 'score': 9.0, 'regions': ['美国']}]}
这里就以第一页的数据为示例来演示了,其他的页面我们通过修改 page 的值就可以拿到了。
总结
以上我们便通过一个样例讲解了一个比较基本的 App 的逆向过程,包括 JEB 的使用、追踪代码的操作等等,最后通过分析代码理清了基本逻辑,最后模拟实现了 API 的参数构造和请求发送,得到最终的数据。